Para preparar dados de valores separados por delimitadores (DSV) para upload, como, por exemplo, para massagear dados tabulares no formato necessário, adicione uma etapa em uma cadeia que use um comando de conexão de transformação tabular. Por exemplo:
- Dividir conjuntos de dados com base no conteúdo de um registro
- Filtrar com base em regras
- Combinar conjuntos de dados de várias fontes
Para habilitar esses comandos, primeiro um administrador de TI cria um conector de transformação tabular.
Adicionar cabeçalho
Para adicionar uma linha de cabeçalho a um arquivo de valores separados por vírgula (CSV), use o comando Add Header.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo ao qual você deseja adicionar os cabeçalhos. |
| Delimitador |
Selecione o delimitador usado para separar as colunas em Arquivo de entrada. |
| Prévia dos resultados |
Para visualizar as dez primeiras linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
| Linha de cabeçalho |
Digite todo o conteúdo da linha de cabeçalho. Separe cada cabeçalho com um delimitador, como, por exemplo, Column1,Column2,Column3. |
| Delimitador de cabeçalho |
Digite o delimitador usado para separar os cabeçalhos em Linha de cabeçalho, como , |
Saídas
| Saída |
Tipo de saída |
| CSV com cabeçalhos |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
Adicionar números de linha
Para adicionar o número da linha ao DSV na primeira coluna, use o comando Add Row Numbers.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo ao qual você deseja adicionar números de linha. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Digite o delimitador usado para separar as colunas em Arquivo de entrada. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Adicionar saída de números de linha |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Consulta avançada
Para executar uma consulta SQL em um ou mais arquivos CSV, use o comando Advanced Query. Você também pode unir outros arquivos que anexar a esse comando.
Observação: Esse comando oferece suporte a instruções SELECT e instruções complementares JOIN, mas não a instruções como INSERT, UPDATE, ou CREATE. Para inserir linhas, use o comando Stack Files; para atualizar linhas, Find and Replace.
Propriedades
| Propriedade |
Detalhes |
| Tabelas |
Digite todos os arquivos a serem usados na consulta, bem como o nome da tabela. |
| Consulta |
Digite a consulta SQL a ser executada, como sintaxe SQLite:
- Se os nomes ou identificadores de colunas contiverem espaços ou caracteres especiais, use colchetes. Por exemplo,
[Coluna A], [Coluna B].
- Para formatar dados com duas casas decimais, use a sintaxe
SELECT PRINTF('%.2f',(SUM(DATA))) AS EBITDA FROM HFMDat.
- Para selecionar a primeira instância de uma duplicata, por exemplo, se dois registros tiverem o mesmo
ID, use a sintaxe select * from group by ID having MIN(ID) ORDER BY ID.
- Para concatenar várias cadeias de caracteres, use o operador
|| como, por exemplo, string1 || string2 [ || string_n ].
|
| Delimitador de entrada |
Selecione o delimitador usado em Tabelas, bem como os arquivos de junção. |
| Delimitador de saída |
Selecione o delimitador a ser usado nos resultados da consulta. |
| Exibição |
Para imprimir uma visualização dos resultados da consulta, marque essa caixa. |
O comando Advanced Query tenta automaticamente determinar o tipo de dados de uma coluna. Para manter os zeros à esquerda em um valor que o comando confunde com um número inteiro, use os comandos Find and Replace - com Regex e Replace correspondências somente selecionadas - para adicionar aspas simples (') em torno dos valores da coluna e, em seguida, removê-las após a conclusão do comando Advanced Query:
- Para adicionar aspas simples, localize
(\d+), e substitua por '$1'.
- Para remover aspas simples, localize
'(\d+)', e substitua por $1.
Com Regex selecionado, o comando Find and Replace usa os parênteses (()) para capturar o grupo ou os caracteres e, em seguida, os substitui como o primeiro parâmetro $1. Para criar várias capturas, use conjuntos subsequentes de parênteses e valores incrementais, como $2.
Saídas
| Saída |
Tipo de saída |
| Resultado |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Alterar delimitador
Para alterar o delimitador de um arquivo CSV, use o comando Change Delimiter.
Observação: Para estar em conformidade com a especificação RFC, sempre use um único caractere como delimitador, de preferência uma vírgula ou um caractere de tabulação.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Delimitador de entrada |
Digite o delimitador usado atualmente em Arquivo de entrada. Para um caractere de tabulação, digite \t. |
| Delimitador de saída |
Digite o delimitador a ser usado após a transformação. Para um caractere de tabulação, digite \t. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
| Manter linhas vazias |
Marque essa caixa para manter as linhas vazias em sua saída. Elas são removidas por padrão. |
Saídas
| Saída |
Tipo de saída |
| Resultado CSV |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
Limpar novas linhas sem aspas
Para tentar limpar um arquivo que esteja em conformidade com a Request for Comments (RFC), exceto no que se refere a caracteres de nova linha não citados, use o comando Clean Unquoted Newlines. Por exemplo, use esse comando para processar arquivos de dados com caracteres inconsistentes para retornos de carro ou novas linhas.
Observação: Esse comando limpa apenas as novas linhas sem aspas. Outros problemas não compatíveis ainda farão com que o conjunto de dados falhe.
Propriedades
| Propriedade |
Detalhes |
| Resultado da visualização |
Para visualizar o resultado no registro do comando, marque essa caixa. |
| Arquivo de entrada |
Digite o arquivo a ser limpo. |
| Delimitador de arquivo |
Selecione o delimitador para cada coluna em Arquivo de entrada. |
| Usar aspas simples |
Para permitir que as aspas apareçam em campos sem aspas e que aspas não duplas apareçam em campos com aspas, marque essa caixa. |
| Anexar texto final |
Para anexar qualquer linha de coluna única sem delimitadores no arquivo de entrada ao último valor da última coluna do registro anterior, marque esta caixa. |
Saídas
| Saída |
Tipo de saída |
| Saída de novas linhas limpas |
Arquivo |
| Contagem de linhas |
Inteiro |
Observação: A saída Line count fornece o número total de registros - incluindo o cabeçalho - na saída Cleaned newlines output.
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Falha ao criar a saída de nova linha limpa |
Filtro de coluna
Para filtrar as colunas DSV com cabeçalhos que correspondam ao padrão especificado, use o comando Column Filter.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Tipo de padrão |
Selecione o tipo de padrão pelo qual você deseja filtrar:
-
Index para filtrar por índice de coluna
-
Exact para filtrar por uma lista de valores exatos separados por vírgula
-
Regex para filtrar por uma expressão regular
|
| Padrão |
Digite o padrão com o qual você deseja fazer a correspondência de colunas. Se Tipo de padrão for Índice, aplique o operador de propagação, como 1:5,7:8,10:15. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
| Inversa |
Para manter as colunas correspondentes e remover todas as outras, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Saída do filtro de coluna |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Arquivos Concat
Para mesclar vários arquivos de fonte de dados tabulares horizontalmente em um único conjunto de dados CSV, use o comando Concat Files.
Propriedades
| Propriedade |
Detalhes |
| Arquivos de origem |
Digite os arquivos a serem concatenados. |
| Resultado da visualização |
Para visualizar o resultado no registro do comando, marque essa caixa. |
| Delimitador de arquivo |
Selecione o delimitador usado em Arquivos de origem. |
Saídas
| Saída |
Tipo de saída |
| CSV mesclado |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Falha ao gerar CSV |
Converter CSV em XLSX
Para converter um arquivo CSV em uma pasta de trabalho do Microsoft Excel® (XLSX), use o comando Convert CSV to XLSX.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser convertido em XLSX. |
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Nome da planilha |
Digite o nome da planilha a ser criada na pasta de trabalho do Excel. |
| Arquivo de saída |
Digite o caminho para o local onde você deseja armazenar o arquivo (opcional). Se você estiver usando como saída para outro comando na cadeia, deixe em branco. |
Saídas
| Saída |
Tipo de saída |
| Saída XLSX |
Arquivo |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
Converter JSON em CSV
Para converter um arquivo JSON em CSV, use o comando Convert JSON to CSV.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo JSON a ser convertido em CSV. |
| Arquivo de saída |
Digite o caminho para onde você deseja salvar o novo arquivo CSV. Se você estiver usando como saída para outro comando na cadeia, deixe em branco. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Saída de CSV |
Arquivo |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
Converter em crosstab
Para converter um conjunto de dados tabulares - como uma saída de consulta Oracle Essbase® multidimensional expressions (MDX) - em uma tabulação cruzada, ou crosstab, use o comando Convert to Cross-Tab. Esse comando baseia o layout da tabela de referência cruzada nos cabeçalhos de coluna e linha definidos como tuplas no conjunto de dados tabulares de entrada.
Por exemplo, com esse comando, você terá esse conjunto de dados:
(Medidas, Produto, Mercado) (Real, Trimestre1) (Real, Trimestre2) (Real, Trimestre3) (Real, Trimestre4) (Orçamento, Trimestre1) (Orçamento, Trimestre2) (Orçamento, Trimestre3) (Orçamento, Trimestre4) (Vendas, 100-10, Nova York) 1995.0 2358,0 2612,0 1972,0 2249,0 2220,0 2470,0 1720,0 (Vendas, 100-10, Massachusetts) 1456,0 1719,0 1905,0 1438,0 1360,0 1620,0 1800,0 1250,0 (Vendas, 100-10, Flórida) 620,0 735.0 821,0 623,0 570,0 690,0 770,0 530,0 (Vendas, 100-10, Connecticut) 944,0 799,0 708,0 927,0 880,0 750,0 660,0 810,0 (Vendas, 100-10, New Hampshire) 353,0 413,0 459,0 345,0 320.0 370,0 430,0 280,0 (Vendas, 100-10, Califórnia) 1998,0 2358,0 2612,0 1972,0 2480,0 2940,0 3250,0 2530,0 (Vendas, 100-10, Oregon) 464,0 347,0 345,0 370,0 570,0 420,0 420,0 470,0
pode se tornar uma tabela cruzada delimitada por tabulação:
Real Real Real Real Real Orçamento Orçamento Orçamento Orçamento Qtr1 Qtr2 Qtr3 Qtr4 Qtr1 Qtr2 Qtr3 Qtr4 Vendas 100-10 Nova York 1995,0 2358,0 2612,0 1972,0 2249,0 2220.0 2470,0 1720,0 Vendas 100-10 Massachusetts 1456,0 1719,0 1905,0 1438,0 1360,0 1620,0 1800,0 1250,0 Vendas 100-10 Flórida 620,0 735,0 821,0 623,0 570,0 690.0 770,0 530,0 Vendas 100-10 Connecticut 944,0 799,0 708,0 927,0 880,0 750,0 660,0 810,0 Vendas 100-10 New Hampshire 353,0 413,0 459,0 345,0 320,0 370,0 430.0 280,0 Vendas 100-10 Califórnia 1998,0 2358,0 2612,0 1972,0 2480,0 2940,0 3250,0 2530,0 Vendas 100-10 Oregon 464,0 347,0 345,0 370,0 570,0 420,0 420,0 470,0
Sconfiguração ampla
A configuração será parecida com a seguinte:
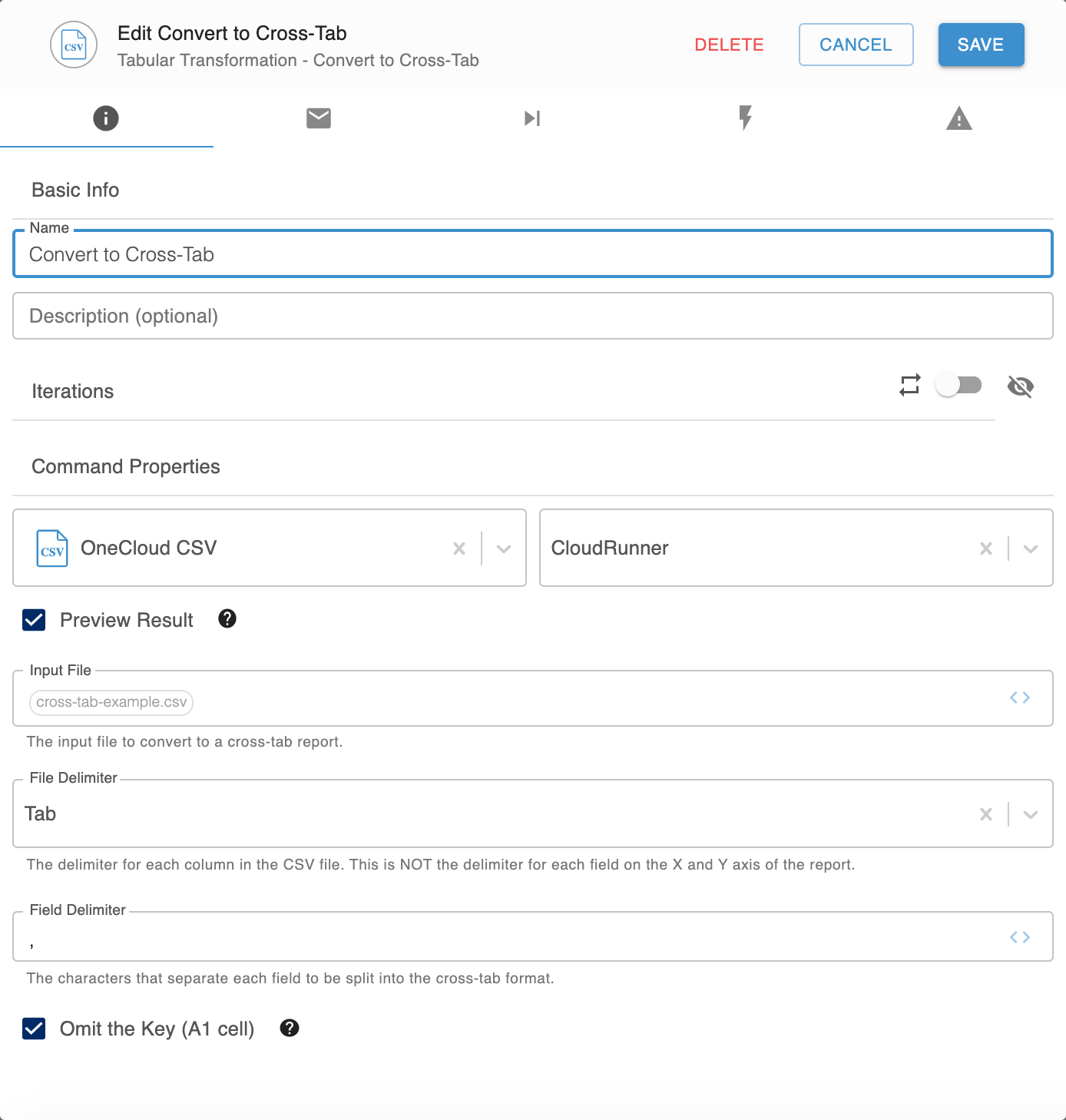
Propriedades
| Propriedade |
Detalhes |
| Resultado da visualização |
Para visualizar o formato de tabela de referência cruzada, marque essa caixa. |
| Arquivo de entrada |
Insira o arquivo a ser convertido em um formato de tabela de referência cruzada, com os cabeçalhos de coluna e linha definidos como tuplas. Observação: Configure o arquivo de entrada de modo que a primeira coluna seja um conjunto delimitado de valores a serem distribuídos horizontalmente e a primeira linha seja um conjunto delimitado de valores a serem distribuídos verticalmente. |
| Delimitador de arquivo |
Selecione o delimitador usado com as colunas em Arquivo de entrada. |
| Delimitador de campo |
Digite o caractere a ser usado para separar cada divisão de campo no formato de tabela de referência cruzada. |
| Omitir a chave (célula A1) |
Para omitir a célula A1 do arquivo de entrada do formato de tabulação cruzada, marque esta caixa. Por exemplo, se a célula A1 contiver (A,B), as células A1 e A2 do formato de tabulação cruzada ficarão em branco; caso contrário, elas conterão A e B. |
Saídas
| Saída |
Tipo de saída |
| Relatório de tabulação cruzada |
Arquivo |
| Contagem de linhas |
Inteiro |
Observação: A saída Line count fornece o número total de linhas na saída do relatório Crosstab, incluindo todas as linhas de cabeçalho.
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
Converter XLSX em CSV
A versão de transformação tabular desse comando foi descontinuada. Todas as cadeias existentes que usam esse comando continuarão funcionando, mas nenhuma instância futura poderá ser criada.
Em vez disso, recomendamos que você use o comando Worksheet to CSV do conector do Excel.
Copiar coluna
Para copiar uma coluna de um arquivo DSV, use o comando Copy Column.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Nome da coluna |
Digite o nome da coluna a ser copiada. |
| Nome da nova coluna |
Digite o nome da cópia resultante da coluna. |
| Inserir índice |
Digite o índice da coluna em que você deseja inserir a cópia da coluna. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Copiar saída da coluna |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado no arquivo de entrada, geralmente um " |
Extrair valor
Para extrair um valor de um arquivo DSV pelo índice de linha e pelo índice de coluna, use o comando Extract Value.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Índice de linha |
Digite o número da linha da qual você deseja extrair o valor, com a primeira linha em Input file sendo 1. |
| Índice de coluna |
Digite o número da coluna da entrada Row index da qual você deseja extrair. Para extrair a linha inteira, deixe em branco. |
Saídas
| Saída |
Tipo de saída |
| Linha |
JSON |
| Valor |
String |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
Filtrar linhas
Para filtrar as linhas do DSV por uma expressão regular (regex) ou pela correspondência exata de uma ou mais colunas na linha, use o comando Filter Rows.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Localizar padrão |
Digite o padrão a ser usado para encontrar correspondências. |
| Tipo de padrão de correspondência |
Selecione se você deseja fazer a correspondência com um padrão Regex ou Exact. |
| Não diferenciar maiúsculas de minúsculas |
Para ignorar as maiúsculas e minúsculas do texto, marque essa caixa. |
| Inverso |
Para manter todas as linhas correspondentes e descartar as demais, marque essa caixa. |
| Colunas de pesquisa |
Insira uma lista separada por vírgulas de índices de coluna para limitar a pesquisa. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque esta caixa |
Observação: O comando Filter Rows espera um arquivo DSV adequado com cabeçalhos. Para filtrar a primeira linha de um arquivo sem os cabeçalhos, use o comando Find de em uma conexão de utilitários de arquivo.
Saídas
| Saída |
Tipo de saída |
| Filtrar a saída da linha |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Input File, geralmente um " |
Localizar e substituir
Para localizar e substituir valores de coluna nos dados com base em uma expressão regular , em uma string de texto completo ou em um índice de coluna, use o comando Find and Replace.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Especifique se você deseja gerar o arquivo original ou uma cópia:
- Para gerar o arquivo original com seus valores de coluna atualizados, digite o mesmo arquivo que Arquivo de entrada.
- Para gerar uma cópia do original com os valores atualizados da coluna, digite o nome do novo arquivo.
|
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Localizar padrão |
Digite a expressão regular, a cadeia de caracteres de texto ou o índice de coluna a ser usado para identificar os valores a serem substituídos, com base em Match pattern type. |
| Tipo de padrão de correspondência |
Selecione como identificar os valores da coluna a serem encontrados:
- Para localizar valores com base em uma expressão regular, selecione
Regex.
- Para localizar valores que correspondam a uma string de texto completo, selecione
Exact.
- Para localizar valores com base em suas colunas, selecione
Index.
Observação: Exact corresponde à cadeia de caracteres completa em cada coluna. Para localizar e substituir um valor parcial por uma coluna, selecione Regex e Replace matches only. |
| Valor de substituição |
Digite o texto para substituir os valores correspondentes. Observação: Se Tipo de padrão de correspondência for Índice, o valor de substituição substituirá todos os valores da coluna correspondente. |
| Não diferenciar maiúsculas de minúsculas |
Para ignorar as maiúsculas e minúsculas do texto, marque essa caixa. |
| Substituir somente correspondências |
Se Match pattern type is Regex, marque essa caixa para substituir apenas o texto correspondente pelo valor de substituição. |
| Prévia dos resultados |
Para visualizar as dez primeiras linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
| Colunas |
Insira uma lista de colunas separada por vírgulas para o escopo do comando, com 0 para a primeira coluna. Por exemplo, 0,1,2,3 limita o comando às quatro primeiras colunas. |
Observação: Para aplicar a mesma entrada Replacement Value a vários valores, use uma expressão regular como entrada Find Pattern, como (?:Variance|Variance %|All Periods|FY15|YTD).
Saídas
| Saída |
Tipo de saída |
| Saída de localização e substituição |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Input File, geralmente um " |
Inserir coluna
Para inserir uma coluna em um arquivo DSV, use o comando Insert Column.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Texto do cabeçalho |
Digite o nome do novo cabeçalho da coluna. |
| Valor dos dados |
Digite o texto a ser inserido na nova coluna. |
| Inserir índice |
Digite o índice da coluna em que você deseja inserir a nova coluna. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque esta caixa. |
Observação: Para inserir várias colunas, adicione uma coluna ao arquivo de entrada com um cabeçalho EMPTY_REPLACED_HEADER, com um valor para cada linha de EMPTY_REPLACED_VALUE. Com a conexão File Utilities, use os comandos Find and Replace para substituir o espaço reservado do cabeçalho pelo cabeçalho da coluna desejada e o espaço reservado do valor por uma cadeia de caracteres com o número de vírgulas necessárias.
Saídas
| Saída |
Tipo de saída |
| Inserir saída de coluna |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Unir colunas
Para unir várias colunas de um arquivo DSV e, opcionalmente, descartar as colunas usadas, use o comando Join Columns.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador de Arquivo de entrada. |
| Índice da coluna unida |
Digite o número de índice da nova coluna. Para a primeira coluna, digite 0. |
| Tipo de padrão de correspondência |
Selecione o tipo de padrão pelo qual você deve pesquisar as colunas:
- Para pesquisar por local da coluna, selecione Index.
- Para inserir uma lista de cabeçalhos separados por vírgula, selecione Exact.
- Para usar a expressão regular , selecione Regex.
|
| Padrão de correspondência |
Insira o padrão ou o índice a ser usado para localizar as colunas a serem unidas. |
| Cabeçalho da coluna unida |
Digite o nome da nova coluna criada a partir da união. |
| Texto da união |
Digite o texto que une os valores na nova coluna, como -. |
| Descartar |
Para remover as colunas unidas para criar a nova, marque essa caixa. |
| Prévia dos resultados |
Para visualizar as primeiras 10 linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Juntar saída de coluna |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Mapear cabeçalhos
Para substituir uma lista de cabeçalhos por outra lista de cabeçalhos, use o comando Map Headers. Nas listas, separe os cabeçalhos por vírgulas e a ordem é importante.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador de Arquivo de entrada. |
| Cabeçalhos de entrada |
Insira uma lista dos cabeçalhos a serem substituídos por novos valores, na mesma ordem de . Cabeçalhos de saída. |
| Cabeçalhos de saída |
Digite uma lista dos novos cabeçalhos a serem incluídos na saída, na mesma ordem que Cabeçalhos de entrada. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
| Usar índices |
Se Os cabeçalhos de entrada usam índices numéricos, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Saída dos cabeçalhos do mapa |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Pivotar
Para representar os valores em uma coluna de dados como colunas separadas, use o comando Pivot. Quando você dinamiza uma coluna, os valores exclusivos de suas linhas se tornam novos cabeçalhos de coluna.
Por exemplo, considerando esses dados:
YEAR,MEASURE,PRODUCT,MARKET,SCENARIO,Period,Amount FY20,Sales,100-10,Massachusetts,Actual,JAN,125 FY20,Sales,100-10,Massachusetts,Actual,FEB,225 AF20,Vendas,100-10,Massachusetts,Real,MAR,325 AF20,Vendas,100-10,Massachusetts,Real,ABR,425 AF20,Vendas,100-10,Massachusetts,Real,MAIO,525 AF20,Vendas,100-10,Massachusetts,Real,JUN,625 AF20,Vendas,100-10,Massachusetts,Real,JUL,725 AF20,Vendas,100-10,Massachusetts,Real,AUG,825 AF20,Vendas,100-10,Massachusetts,Real,SEP,925 AF20,Vendas,100-10,Massachusetts,Real,OUT,1025 AF20,Vendas,100-10,Massachusetts,Real,NOV,1125 AF20,Vendas,100-10,Massachusetts,Real,DEZ,1225 AF20,CPV,100-10,Massachusetts,Real,JAN,100 AF20,CPV,100-10,Massachusetts,Real,FEV,200 AF20,CPV,100-10,Massachusetts,Real,MAR,300 AF20,CPV,100-10,Massachusetts,Real,ABR,400 AF20,CPV,100-10,Massachusetts,Real,MAIO,500 AF20,CPV,100-10,Massachusetts,Real,JUN,600 AF20,CPV,100-10,Massachusetts,Real,JUL,700 AF20,CPV,100-10,Massachusetts,Real,AUG,800 AF20,CPV,100-10,Massachusetts,Real,SEP,900 FY20,COGS,100-10,Massachusetts,Real,OCT,1000 FY20,COGS,100-10,Massachusetts,Real,NOV,1100 FY20,COGS,100-10,Massachusetts,Real,DEC,1200
Se você dinamizar a coluna MEASURE, agregar a coluna Amount e especificar as colunas restantes como linhas, a saída substituirá a coluna MEASURE por colunas para os valores Sales e COGS e fornecerá seus respectivos valores:
YEAR,PRODUCT,MARKET,SCENARIO,Period,Sales,COGS FY20,100-10,Massachusetts,Actual,APR,425,400 FY20,100-10,Massachusetts,Actual,AUG,825,800 FY20,100-10,Massachusetts,Actual,DEC,1225,1200 FY20,100-10,Massachusetts,Actual,FEB,225,200 FY20,100-10,Massachusetts,Actual,JAN,125,100 FY20,100-10,Massachusetts,Actual,JUL,725,700 FY20,100-10,Massachusetts,Actual,JUN,625,600 FY20,100-10,Massachusetts,Actual,MAR,325,300 FY20,100-10,Massachusetts,Actual,MAY,525,500 FY20,100-10,Massachusetts,Actual,NOV,1125,1100 FY20,100-10,Massachusetts,Actual,OCT,1025,1000 FY20,100-10,Massachusetts,Actual,SEP,925,900
Se você excluir a coluna Period das linhas, todos os períodos de tempo serão agregados para cada combinação das linhas restantes:
ANO,PRODUTO,MERCADO,CENÁRIO,Vendas,CPV FY20,100-10,Massachusetts,Real,8100,7800
Se você dinamizar as colunas MEASURE e Period, cada combinação exclusiva de seus valores aparecerá como colunas, como Sales-JAN, Sales-FEB, COGS-JAN, e assim por diante:
ANO,PRODUTO,MERCADO,CENÁRIO,Vendas-JAN,Vendas-FEV,Vendas-MAR,Vendas-APR,Vendas-MAY,Vendas-JUN,Vendas-JUL,Vendas-AGU,Vendas-SEP,Vendas-OCT,Vendas-NOV,Vendas-DEC,COGS-JAN,COGS-FEB,COGS-MAR,COGS-APR,COGS-MAY,COGS-JUN,COGS-JUL,COGS-AUG,COGS-SEP,COGS-OCT,COGS-NOV,COGS-DEC FY20,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225,100,200,300,400,500,600,700,800,900,1000,1100,1200
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Insira o arquivo com os dados a serem dinamizados. |
| Delimitador |
Selecione o delimitador usado para separar os campos em Arquivo de entrada. |
| Agregação |
Selecione como agregar valores dinamizados:
- SUM, para recolher registros com os mesmos valores de linha em um único registro. Recomendado:
- NONE, para criar várias linhas para um único conjunto de valores equivalentes. Cada linha da coluna dinamizada será preenchida, mas as outras podem incluir NULL.
|
| Valores a serem agregados |
Insira a coluna com os dados a serem incluídos nas linhas das colunas dinâmicas, como a coluna Amount no exemplo anterior. |
| Colunas dinâmicas |
Insira as colunas com valores de linha a serem usados como cabeçalhos de coluna. Se você tiver várias colunas, uma coluna separada aparecerá para cada combinação exclusiva de seus valores. |
| Delimitador de coluna |
Se você tiver vários Colunas dinâmicas, digite o delimitador a ser usado para separar seus valores nos novos cabeçalhos de coluna. |
| Linhas dinâmicas |
Insira as colunas em Arquivo de entrada para manter. Na saída, cada combinação exclusiva dos valores dessas colunas aparece como linhas. Do not insira as mesmas colunas que Valores para agregar ou Colunas dinâmicas. |
| Prévia dos resultados |
Para ativar uma visualização dos dados dinamizados, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Resultado dinamizado |
Arquivo |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Reordenar colunas
Para reorganizar as colunas de um arquivo DSV, use o comando Reorder columns (Reordenar colunas). Você pode identificar as colunas por seu nome ou índice.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Ordens das colunas |
Insira uma matriz de colunas ou intervalos individuais de Arquivo de entrada, na ordem em que devem aparecer no arquivo transformado. Para especificar colunas, use o nome ou o índice delas, começando com 1. Por exemplo, digite 4:6 ou ColA:ColC para especificar um intervalo, ou 7 ou ColH para uma coluna individual. Observação: Quaisquer colunas em Arquivo de entrada não incluídas em Ordens de coluna aparecem no final das colunas do arquivo transformado, na mesma ordem que em Arquivo de entrada. |
| Prévia dos resultados |
Para mostrar uma visualização dos resultados - o cabeçalho e as primeiras 10 linhas - na saída do comando, marque esta caixa. |
Saídas
| Saída |
Tipo de saída |
| Arquivo transformado |
Arquivo |
| Linhas transformadas |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
Linhas de filtro inteligentes
Para aplicar os critérios de vários grupos de filtros - com base em valores de texto, data ou número - às linhas de um arquivo DSV, use o comando Smart Filter Rows. Você pode filtrar as linhas pela expressão regular ou por uma correspondência exata de uma ou mais de suas colunas.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador usado em Arquivo de entrada. |
| Inversa |
Para manter - em vez de remover - todas as linhas que correspondam a Filtros, marque esta caixa. |
| Filtros |
Para configurar os filtros de texto, número ou data a serem aplicados a Arquivo de entrada, selecione o operador para os grupos de filtros - AND ou OR - e configure os critérios para cada um deles. Para um grupo de filtros text:
- Em Column Name, digite o nome da coluna a ser filtrada.
- Para ignorar a caixa de Column Name e Compare Text, selecione Case Insensitive.
- Em Condition e Compare Text, insira os critérios do valor a ser pesquisado na coluna, como "Equals [text]" ou "Contains [text]". <!--To apply
the inverse of the Condition
input, such as to match text that does not
equal or contain the Compare Text
input, select Not.-->
<!---
To remove any leading or trailing spaces from
matched text, select Trim.
-->
Para um número grupo de filtros:
- Em Format, selecione o formato do número a ser correspondido - inteiro ou decimal. Se puder ser qualquer um deles, selecione Decimal.
- Em Column Name, digite o nome da coluna a ser filtrada.
- Em Condição e Número de teste, insira os critérios do valor a ser pesquisado na coluna, como "Igual a [número]" ou "Menor que [número]". <!--To apply the inverse
of the Condition input,
such as to match numbers that do not
equal the Test Number input,
select Not.-->
<!---
To match numbers regardless of whether they're
positive or negative, select Absolute Value.
-->
Para um grupo de filtros date:
- Em Format, digite 2 de janeiro de 2006 no formato da data a ser correspondida, como 2006-01-02.
- Em Column Name, digite o nome da coluna a ser filtrada.
- Em Condition e Compare Date, insira os critérios do valor a ser pesquisado na coluna, como "Equals [date]" ou "Less than [date]". <!--To
apply the inverse of the Condition
input, such as to match dates that do not
equal the Compare Date
input, select Not.-->
|
| Prévia dos resultados |
Para mostrar uma visualização dos resultados na saída do comando, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Saída de linha de filtro inteligente |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Dividir arquivo
Para dividir um arquivo em vários arquivos com base em uma contagem de registros, use o comando Split File. Por exemplo, use este comando para processar pedaços menores em paralelo para ajudar a melhorar o desempenho
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser dividido em vários arquivos. |
| Delimitador de arquivo |
Selecione o delimitador para cada coluna em Arquivo de entrada. |
| Anexar cabeçalho |
Para incluir o cabeçalho de Arquivo de entrada em cada bloco de arquivo criado, marque essa caixa. |
| Registros por arquivo |
Digite o número máximo de registros a serem incluídos em cada bloco de arquivo. |
Saídas
| Saída |
Tipo de saída |
| Dividir pedaços de arquivos |
Arquivo |
| Número de blocos |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Falha ao criar os pedaços de arquivo |
Dividir valor
Para dividir uma coluna em várias colunas com um delimitador de valor, use o comando Split Value.
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Digite o arquivo a ser transformado. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador usado para separar as colunas em Arquivo de entrada. |
| Novos cabeçalhos |
Digite uma lista dos novos cabeçalhos a serem criados a partir do valor de divisão, em ordem. |
| Nome da coluna |
Digite o cabeçalho da coluna a ser dividida. |
| Delimitador de valor |
Digite o delimitador para dividir o valor. |
| Descartar coluna |
Para remover a coluna que está sendo dividida, marque essa caixa. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Saída de valores divididos |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Arquivos de pilha
Para empilhar os valores de uma lista de arquivos de valores separados por delimitadores (DSV) uns sobre os outros em uma ordem especificada, use o comando Stack Files. A linha de cabeçalho do primeiro arquivo será usada no novo arquivo.
Observação: Para empilhar arquivos com esse comando, todos eles devem ter o mesmo número de colunas. Para empilhar arquivos assimétricos, use o conector File Utils e o comando Stack Files.
Propriedades
| Propriedade |
Detalhes |
| Arquivos |
Digite os arquivos DSV a serem empilhados. |
| Arquivo de saída |
Digite o nome do arquivo resultante da transformação. |
| Delimitador |
Selecione o delimitador usado para separar as colunas em Files. |
| Arquivo de entrada |
Digite os arquivos a serem empilhados, separados por vírgula. Observação: Ao usar um loop, esse campo é obrigatório (devido ao fato de os arquivos não serem carregados na seção Files). O comando acionará um erro de "arquivo não encontrado" se for adicionado à seção Arquivos. |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Saída de arquivos de pilha |
Arquivo |
| Contagem de registros |
Inteiro |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Transpor
Para girar todos os campos de um arquivo delimitado ao longo de seus eixos horizontal e vertical, de modo que as linhas se tornem colunas e vice-versa, use o comando Transpose. Por exemplo, com esse comando, você pode obter esse CSV:
id,1,2,3,4
name, "Johnson, Smith, and Jones Co.", "Sam Smith",Barney & Co.,Johnson's Auto
amount,345.33,933.40,0,2344
remark,Pays on time,, "Great to work with.",
torna-se:
id,name,amount,remark
1, "Johnson, Smith, and Jones Co",345.33,Pays on time
2, "Sam Smith",933.40,
3,Barney & Co., "Great to work with."
4,Johnson's Auto,2344,
Propriedades
| Propriedade |
Detalhes |
| Prévia dos resultados |
Para visualizar as primeiras dez linhas e o cabeçalho dos resultados da transformação, marque essa caixa. |
| Arquivo de entrada |
Digite o arquivo delimitado a ser transposto. |
| Delimitador de arquivo |
Selecione o delimitador de cada coluna de Arquivo de entrada. |
| Tamanho do pedaço |
Insira o tamanho máximo - em MB - de cada arquivo de trabalho para processamento. |
Saídas
| Saída |
Tipo de saída |
| CSV transposto |
Arquivo |
| Contagem de registros |
Inteiro |
Observação: Record Count fornece o número total de linhas em Transposed CSV, e não, incluindo a linha do cabeçalho.
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Falha ao transpor o arquivo de entrada |
Unpivot
Para consolidar várias colunas de dados - como períodos de tempo em dados financeiros - em uma única coluna com várias linhas, use o comando Unpivot. Por exemplo, com base nesses dados:
ANO,MEDIDA,PRODUTO,MERCADO,CENÁRIO,JAN,FEV,MAR,ABR,MAIO,JUN,JUL,AGOSTO,SET,OUT,NOV,DEZ AF20,Vendas,100-10,Nova York,Real,100,200,300,400,500,600,700,800,900,1000,1100,1200 FY20,Sales,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225
Você pode desdobrar os valores mensais em novas colunas Period e Amount:
ANO,MEDIDA,PRODUTO,MERCADO,CENÁRIO,Período,Valor AF20,Vendas,100-10,Massachusetts,Real,JAN,125 AF20,Vendas,100-10,Massachusetts,Real,FEV,225 AF20,Vendas,100-10,Massachusetts,Real,MAR,325 AF20,Vendas,100-10,Massachusetts,Real,ABR,425 AF20,Vendas,100-10,Massachusetts,Real,MAIO,525 AF20,Vendas,100-10,Massachusetts,Real,JUN,625 AF20,Vendas,100-10,Massachusetts,Real,JUL,725 AF20,Vendas,100-10,Massachusetts,Real,AUG,825 AF20,Vendas,100-10,Massachusetts,Real,SEP,925 AF20,Vendas,100-10,Massachusetts,Real,OUT,1025 AF20,Vendas,100-10,Massachusetts,Real,NOV,1125 AF20,Vendas,100-10,Massachusetts,Real,DEZ,1225 AF20,Vendas,100-10,Nova York,Real,JAN,100 AF20,Vendas,100-10,Nova York,Real,FEV,200 AF20,Vendas,100-10,Nova York,Real,MAR,300 AF20,Vendas,100-10,Nova York,Real,ABR,400 AF20,Vendas,100-10,Nova York,Real,MAIO,500 AF20,Vendas,100-10,Nova Iorque,Real,JUN,600 AF20,Vendas,100-10,Nova Iorque,Real,JUL,700 AF20,Vendas,100-10,Nova Iorque,Real,AGO,800 AF20,Vendas,100-10,Nova Iorque,Real,SET,900 AF20,Vendas,100-10,Nova Iorque,Real,OUT,1000 AF20,Vendas,100-10,Nova Iorque,Real,NOV,1100 AF20,Vendas,100-10,Nova Iorque,Real,DEZ,1200
Propriedades
| Propriedade |
Detalhes |
| Arquivo de entrada |
Insira o arquivo com os dados a serem dinamizados. |
| Delimitador |
Selecione o delimitador usado para separar os campos em Arquivo de entrada. |
| Agregação |
Selecione como agregar valores não dinamizados:
- SUM, para agregar registros quando os valores forem iguais em todas as colunas. Recomendado:
- NONE, para criar linhas duplicadas com o valor de dados exclusivo de cada registro.
|
| Novo rótulo de coluna |
Digite o cabeçalho da coluna na saída com as linhas baseadas nas colunas não dinamizadas. No exemplo anterior, Período. |
| Cabeçalho da coluna de dados |
Digite o cabeçalho da coluna na saída com dados para as colunas não dinamizadas. No exemplo anterior, Amount. |
| Cabeçalhos de dados |
Para desvincular colunas específicas de, liste seus cabeçalhos, pressionando Enter entre cada um. No exemplo anterior, JAN, FEB, MAR, e assim por diante. |
| Nome da coluna de pivô inicial |
Para desvincular um intervalo de colunas por cabeçalho, digite o nome da primeira coluna do intervalo. No exemplo anterior, JAN. |
| Nome da coluna de pivô final |
Para desvincular um intervalo de colunas por cabeçalho, digite o nome da última coluna do intervalo. No exemplo anterior, DEC. Observação: Se você digitar Nome da coluna de pivô inicial mas não Nome da coluna de pivô final, o comando o desvincula e todas as colunas à direita de Nome da coluna de pivô inicial. Isso pode ser útil com dados produzidos por previsões contínuas. |
| Início do índice da coluna de pivô |
Para desvincular um intervalo de colunas por posição, digite o valor do índice da primeira coluna do intervalo. Use um índice baseado em zero, em que as colunas em Arquivo de entrada começam com 0. No exemplo anterior, 5. |
| Fim do índice da coluna de pivô |
Para desvincular um intervalo de colunas por posição, digite o valor do índice da última coluna do intervalo. Use um índice baseado em zero, em que as colunas em Arquivo de entrada começam com 0. No exemplo anterior, 16. Observação: Se você digitar Starting pivot column index mas no Ending pivot column index, o comando o anula e todas as colunas à direita de Starting pivot column index. Isso pode ser útil com dados produzidos por previsões contínuas. |
| Prévia dos resultados |
Para ativar uma visualização do resultado não pivotado, marque essa caixa. |
Saídas
| Saída |
Tipo de saída |
| Resultado não pivotado |
Arquivo |
Códigos de saída
| Código |
Tipo |
Detalhes |
| 0 |
Sucesso |
Sucesso |
| 1 |
Erro |
Argumentos inválidos |
| 2 |
Erro |
Falha geral |
| 14 |
Erro |
Local do arquivo de saída inválido |
| 15 |
Erro |
O caractere de escape usado em Arquivo de entrada, geralmente um " |
Solução de problemas
Se um comando falhar, verifique se há esses problemas comuns.
Delimitador incorreto
Se o delimitador errado for definido quando você configurar um comando de transformação, a transformação não será executada conforme o esperado.
Não é um CSV adequado
Se o conjunto de dados tabulares não for um CSV adequado, o comando de transformação não será executado, pois ele verifica se o formato está em conformidade com a RFC 4180 antes de processar a entrada. Um CSV adequado:
- Armazena dados em texto simples usando um conjunto de caracteres como ASCII, Unicode (por exemplo, UTF-8), EBCDIC ou Shift JIS.
- Consiste em registros com um registro por linha e registros divididos em campos separados por delimitadores, geralmente um único caractere reservado, como vírgula, ponto e vírgula ou tabulação. Às vezes, o delimitador pode incluir espaços opcionais.
- Tem a mesma sequência de campos para todos os registros
- Normalmente, é um arquivo simples ou uma saída de relatório de dados relacionais
Número inconsistente de colunas em cada registro
Se os registros em um conjunto de dados tabulares tiverem contagens de colunas diferentes, o comando de transformação detectará que não se trata de um CSV adequado.
Contagens de colunas diferentes
A combinação de dois conjuntos de dados tabulares CSV adequados com diferentes contagens de colunas não funcionará, e o comando Stack Files exibirá um erro.