表形式データを必要な書式にマッサージするなど、アップロード用に区切り文字で区切られた値(DSV)データを準備するには、表形式変換接続コマンドを使用するチェーンのステップを追加します。例:
- レコードのコンテンツに基づいてデータセットを分割する
- ルールに基づくフィルター
- 複数のソースからのデータセットを結合する
これらのコマンドを有効にするには、まずIT管理者が表変換コネクタを作成します。
ヘッダー追加
カンマ区切り値(CSV)ファイルにヘッダー行を追加するには、Add Header コマンドを使用する。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
ヘッダーを追加するファイルを入力します。 |
| 区切り記号 |
入力ファイル で列の区切りに使用するデリミタを選択する。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
| ヘッダー行 |
ヘッダー行のコンテンツ全体を入力する。各ヘッダーは、Column1,Column2,Column3 のように区切り文字で区切ります。 |
| ヘッダーデリミター |
ヘッダー行 のヘッダーを区切るために使用される区切り文字を、 のように入力する、 |
出力
| 出力 |
出力タイプ |
| ヘッダー付きCSV |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
行番号の追加
最初の列のDSVに行番号を追加するには、Add Row Numbers コマンドを使用する。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
行番号を追加するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル の列の区切りに使用する区切り文字を入力する。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| 行番号の追加出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
高度なクエリ
1つまたは複数のCSVファイルに対してSQLクエリを実行するには、Advanced Query コマンドを使用します。このコマンドに添付した他のファイルを結合することもできる。
注: このコマンドは、SELECTステートメントおよび補完的なJOINステートメントをサポートしますが、 INSERT,UPDATE, またはCREATE のような ステートメントはサポートしていません。行を挿入するには、ファイルをスタックコマンドを使用します。行を更新するには、検索と置換を使用します。
プロパティ
| プロパティ |
詳細 |
| テーブル |
クエリで使用するすべてのファイルとそのテーブル名称を入力する。 |
| クエリ |
SQLite構文として、実行するSQLクエリを入力します:
- 列名称や識別子が空白や特殊文字を含む場合は、かっこを使用します。例えば、
[列A], [列B] 。
- 小数2型のスペースを持つデータを書式設定するには、
SELECT PRINTF('%.2f',(SUM(DATA))) を選択します。AS EBITDA FROM HFMDat構文を使用します。
- 2つのレコードが同じ
IDを持つ場合など、複製の最初のインスタンスを選択するには、select * from group by ID having MIN(ID) ORDER BY ID構文を使用します。
- 複数の文字列を連結するには、
string1 || string2 [ || string_n ] のように、|| 演算子を使う。
|
| 入力区切り文字 |
テーブル で使用される区切り文字と結合ファイルを選択する。 |
| 出力デリミター |
クエリ結果で使用する区切り文字を選択します。 |
| プレビュー |
クエリ結果のプレビューを印刷するには、このボックスをチェックします。 |
Advanced Query コマンドは、自動的に列のデータ型を決定しようとします。コマンドが整数に対して間違えた値の先頭のゼロを保持するには、検索と置換 コマンド(Regexと一致のみを置換が選択されている)を使用して、列の値の周りにシングルクォート(')を追加し、高度なクエリコマンドが完了した後に削除します:
- シングルクォートを追加するには、
( \d+)を検索し、'$1'で置換します。
- シングルクォートを削除するには、
'( \d+)'を検索し、$1で置換します。
Regex を選択した状態で、Find and Replace コマンドは、括弧 (()) を使ってグループまたは文字を捕捉し、最初のパラメータ$1 として置換します。複数のキャプチャを作成するには、$2 のように、括弧と増分値のセットを使用する。
出力
| 出力 |
出力タイプ |
| 結果 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
区切り文字の変更
CSVファイルのデリミターを変更するには、Change Delimiter コマンドを使用する。
注: RFC仕様に準拠するため、 区切り文字には常に1文字、できればカンマかタブ文字を使用してください。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 入力区切り文字 |
入力ファイル で現在使用されている区切り文字を入力する。タブ文字は、 \tと入力します。 |
| 出力デリミター |
変換後に使用する区切り文字を入力します。タブ文字は、 \tと入力します。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
| 空行を保持する |
出力に空行を維持するには、このボックスをチェックします。デフォルトで削除されている。 |
出力
| 出力 |
出力タイプ |
| CSV結果 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
引用符で囲まれていないきれいな改行
引用符で囲まれていない新規行文字を除き、RFC(Request for Comments)に準拠したファイルのクリーニングを試みるには、Clean Unquoted Newlines コマンドを使用する。例えば、キャリッジ・リターンや新規行の文字が不統一なデータ・ファイルを処理するには、このコマンドを使用する。
メモ: このコマンドは引用符で囲まれていない新規行だけをクリーニングする。その他の非準拠の問題でも、データ設定は失敗する。
プロパティ
| プロパティ |
詳細 |
| プレビュー結果 |
コマンドのログで結果をプレビューするには、このボックスをチェックする。 |
| 入力ファイル |
クリーニングするファイルを入力します。 |
| ファイル区切り記号 |
入力ファイル の各列の区切り文字を選択する。 |
| ダラダラと引用符を使う |
引用符のないフィールドに引用符を表示し、引用符のあるフィールドに二重引用符以外の引用符を表示するには、このボックスにチェックを入れます。 |
| 末尾のテキストを追加する |
入力ファイルに区切りのない1列の行を以前のレコードの最後の列の値に追加するには、このボックスにチェックを入れます。 |
出力
| 出力 |
出力タイプ |
| クリーンな改行出力 |
ファイル |
| 線数 |
整数 |
メモ: 行数 出力は、クリーン改行出力 出力内のヘッダーを含むレコードの総数を提供する。
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
クリーンな改行出力の作成に失敗 |
列フィルター
指定されたパターンに一致するヘッダーを持つDSV列をフィルターするには、Column Filter コマンドを使用します。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| パターン別 |
フィルターするパターンのタイプを選択する:
-
インデックス 列のインデックスでフィルターをかける。
-
Exact カンマで区切られた正確な値のリストでフィルターをかける。
-
Regex正規表現でフィルターをかける
|
| パターン |
列をマッチさせるパターンを入力する。パターンタイプ がインデックス の場合、1:5,7:8,10:15 のようにスプレッド演算子を適用する。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
| インバース |
一致した列を残し、それ以外を削除するには、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| 列フィルター出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
ファイルの連結
複数の表データ ソース ファイルを 1 つの CSV データセットに水平方向にマージするには、Concat Files コマンドを使用します。
プロパティ
| プロパティ |
詳細 |
| ソースファイル |
連結するファイルを入力する。 |
| プレビュー結果 |
コマンドのログで結果をプレビューするには、このボックスをチェックする。 |
| ファイル区切り記号 |
ソースファイル で使用する区切り文字を選択する。 |
出力
| 出力 |
出力タイプ |
| マージされたCSV |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
CSV生成に失敗しました。 |
CSVからXLSXへの変換
CSVファイルをMicrosoft Excel®ワークブック(XLSX)に変換するには、Convert CSV to XLSX コマンドを使用します。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
XLSXに変換するファイルを入力します。 |
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| シート名 |
Excelワークブックに作成するシートの名称を入力します。 |
| 出力ファイル |
ファイルを保存する場所のパスを入力します(オプション)。チェーン内の別のコマンドの出力として使用する場合は、空白のままにする。 |
出力
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
JSONからCSVへの変換
JSONファイルをCSVに変換するには、Convert JSON to CSV コマンドを使用する。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
CSVに変換するJSONファイルを入力します。 |
| 出力ファイル |
新規CSVファイルの保存先パスを入力します。チェーン内の別のコマンドの出力として使用する場合は、空白のままにする。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
出力
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
クロス集計への変換
Oracle Essbase® 多次元式 (MDX) クエリ出力のような表データセットをクロス集計 (crosstab) 書式設定に変換するには、Convert to Cross-Tab コマンドを使用します。このコマンドは、入力表データ設定内のタプルとして定義された列ヘッダーと行ヘッダーを基にクロス集計レイアウトを行う。
例えば、このコマンドで、このデータセット:
(Measures, Product, Market) (Actual, Qtr1) (Actual, Qtr2) (Actual, Qtr3) (Actual, Qtr4) (Budget, Qtr1) (Budget, Qtr2) (Budget, Qtr3) (Budget, Qtr4) (Sales, 100-10, New York) 1995.0 2358.0 2612.0 1972.0 2249.0 2220.0 2470.0 1720.0 (Sales, 100-10, Massachusetts) 1456.0 1719.0 1905.0 1438.0 1360.0 1620.0 1800.0 1250.0 (Sales, 100-10, Florida) 620.0 735.0 821.0 623.0 570.0 690.0 770.0 530.0 (Sales, 100-10, Connecticut) 944.0 799.0 708.0 927.0 880.0 750.0 660.0 810.0 (Sales, 100-10, New Hampshire) 353.0 413.0 459.0 345.0 320.0 370.0 430.0 280.0 (Sales, 100-10, California) 1998.0 2358.0 2612.0 1972.0 2480.0 2940.0 3250.0 2530.0 (Sales, 100-10, Oregon) 464.0 347.0 345.0 370.0 570.0 420.0 420.0 470.0
はタブ区切りのクロス集計になる:
Actual Actual Actual Actual Budget Budget Budget Budget Qtr1 Qtr2 Qtr3 Qtr4 Qtr1 Qtr2 Qtr3 Qtr4 Sales 100-10 New York 1995.0 2358.0 2612.0 1972.0 2249.0 2220.0 2470.0 1720.0 Sales 100-10 Massachusetts 1456.0 1719.0 1905.0 1438.0 1360.0 1620.0 1800.0 1250.0 Sales 100-10 Florida 620.0 735.0 821.0 623.0 570.0 690.0 770.0 530.0 Sales 100-10 Connecticut 944.0 799.0 708.0 927.0 880.0 750.0 660.0 810.0 Sales 100-10 New Hampshire 353.0 413.0 459.0 345.0 320.0 370.0 430.0 280.0 Sales 100-10 California 1998.0 2358.0 2612.0 1972.0 2480.0 2940.0 3250.0 2530.0 Sales 100-10 Oregon 464.0 347.0 345.0 370.0 570.0 420.0 420.0 470.0
十分な構成
セットアップは次のようになる:
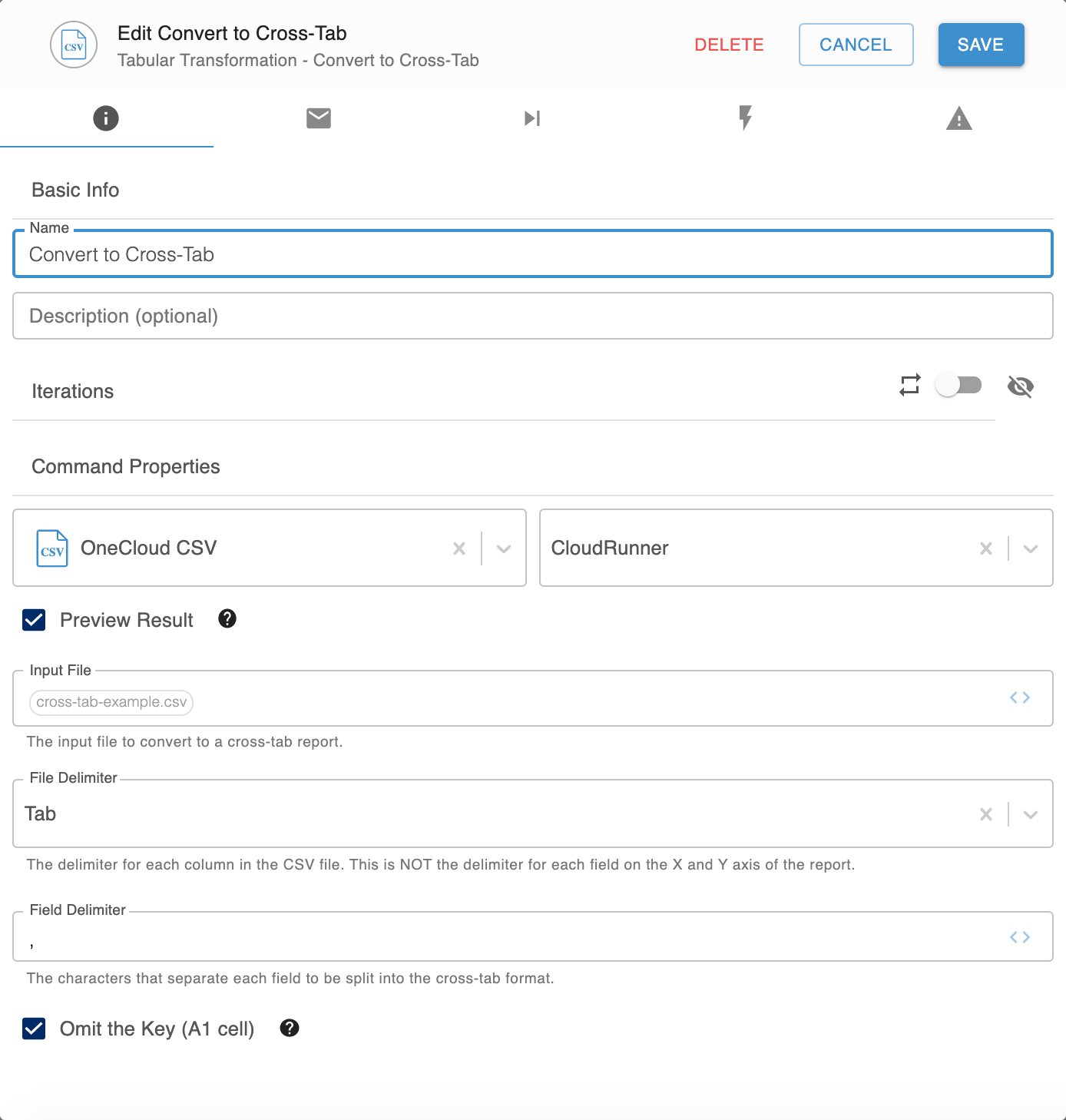
プロパティ
| プロパティ |
詳細 |
| プレビュー結果 |
クロス集計書式設定をプレビューするには、このボックスをチェックします。 |
| 入力ファイル |
列と行のヘッダーをタプルとして定義したクロス集計書式に変換するファイルを入力する。 メモ: 入力ファイルの最初の列は、水平方向に広げる値の区切り設定とし、最初の行は、垂直方向に広げる値の区切り設定とする。 |
| ファイル区切り記号 |
入力ファイル の列で使用される区切り文字を選択する。 |
| フィールド・デリミター |
クロス集計の書式に分割された各フィールドの区切りに使用する文字を入力します。 |
| キーを省略(A1セル) |
入力ファイル のセル A1 をクロス集計の書式設定から省くには、このボックスにチェックを入れる。例えば、セルA1が(A,B)を含む場合、クロスタブ書式のセルA1とA2は空白となり、含まない場合はAとBが含まれる。 |
出力
| 出力 |
出力タイプ |
| クロス集計レポート |
ファイル |
| 線数 |
整数 |
メモ: 行数 出力は、すべてのヘッダー行を含む、クロス集計レポート 出力の総行数を提供する。
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
XLSXからCSVへの変換
このコマンドのタブラー変換バージョンは廃止されました。このコマンドを使用した既存のチェーンは機能し続けるが、今後インスタンスを作成することはできない。
代わりに、Excel コネクターの Worksheet to CSV コマンド を使用することをお勧めします。
コピー列
DSVファイルから列をコピーするには、Copy Column コマンドを使用する。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| 列名 |
コピーする列の名称を入力する。 |
| 新規列名称 |
結果の列のコピーの名称を入力する。 |
| インデックス挿入 |
列のコピーを挿入する列インデックスを入力する。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| コピー列出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
抽出値
DSVファイルから行インデックスと列インデックスによって値を抽出するには、Extract Value コマンドを使用します。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| 行インデックス |
入力ファイル の最初の行を1 として、値を抽出する行番号を入力する。 |
| 列インデックス |
行インデックス 入力から抽出する列番号を入力。行全体を抽出する場合は空白にする。 |
出力
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
フィルター列
、正規表現 (regex)または行内の1つ以上の列の完全一致によってDSVの行をフィルターするには、Filter Rows コマンドを使用する。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| パターン検索 |
検索に使用するパターンを入力します。 |
| マッチパターンタイプ |
Regex またはExact のどちらのパターンでマッチするかを選択します。 |
| 大文字と小文字を区別しない |
テキストの大文字小文字を無視するには、このボックスをチェックします。 |
| インバース |
マッチした行をすべて残し、残りを破棄するには、このボックスをチェックする。 |
| 検索列 |
検索を制限する列インデックスをカンマ区切りで入力する。 |
| プレビュー結果 |
変換の結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックします。 |
メモ: フィルター行 コマンドは、ヘッダー付きの適切なDSVファイルを想定している。ヘッダーのないファイルの最初の行をフィルターするには、ファイルユーティリティ接続 の検索 コマンドを使用します。
出力
| 出力 |
出力タイプ |
| フィルター列出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
検索と置換
正規表現 、フルテキスト文字列、または列インデックスに基づいてデータ内の列値を検索および置換するには、検索および置換 コマンドを使用します。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
オリジナルファイルを出力するか、コピーを出力するかを指定する:
- 列値を更新したオリジナルファイルを出力するには、入力ファイル と同じファイルを入力する。
- 列の値を更新したオリジナルのコピーを出力するには、新規ファイルの名称を入力する。
|
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| パターン検索 |
置換する値を特定するために使用する正規表現、テキスト文字列、または列インデックスを、Match pattern type に基づいて入力する。 |
| マッチパターンタイプ |
検索する列値の識別方法を選択する:
- 正規表現に基づいて値を検索するには、
Regex を選択する。
- 完全なテキスト文字列に一致する値を検索するには、
Exact を選択します。
- 列に基づいて値を検索するには、
インデックス を選択する。
注: Exactは、各列内の完全文字列と一致します。部分値 を列で検索置換するには、Regex とReplace matches only を選択します。 |
| 置換値 |
一致した値を置換するテキストを入力する。 メモ: マッチパターンタイプ がインデックス の場合、置換値はマッチした列の値をすべて置き換えます。 |
| 大文字と小文字を区別しない |
テキストの大文字小文字を無視するには、このボックスをチェックします。 |
| 置換マッチのみ |
Match pattern type がRegex の場合、一致するテキストのみを置換値で置換するには、このボックスにチェックを入れます。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
| 列 |
コマンドをスコープする列のリストをカンマ区切りで入力する。最初の列は0 とする。例えば、0,1,2,3で、コマンドは最初の4列に限定されます。 |
メモ: 同じ置換値 入力を複数の値に適用するには、検索パターン 入力として正規表現を使用する。例えば、(?:Variance|Variance %|All Periods|FY15|YTD) のようにする。
出力
| 出力 |
出力タイプ |
| 検索置換出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
列を挿入
DSVファイルに列を挿入するには、Insert Column コマンドを使用します。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| ヘッダーテキスト |
新規列ヘッダーの名称を入力する。 |
| データ値 |
新規列に挿入するテキストを入力する。 |
| インデックス挿入 |
新規列を挿入する列インデックスを入力する。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
メモ: 複数の 列を挿入するには、EMPTY_REPLACED_HEADER のヘッダーを持つ列を入力ファイルに追加し、EMPTY_REPLACED_VALUE の各行の値を指定する。ファイルユーティリティ接続 で、検索と置換 コマンドを使用して、ヘッダーのプレースホルダーを希望の列ヘッダーに置換し、値のプレースホルダーを必要な数のカンマの文字列に置換する。
出力
| 出力 |
出力タイプ |
| 列挿入出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
列の結合
DSVファイルの複数の列を結合し、オプションで使用された列を破棄するには、Join Columns コマンドを使用します。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル の区切り文字を選択。 |
| 結合列インデックス |
新規列の番号インデックスを入力する。最初の列には0 と入力する。 |
| マッチパターンタイプ |
列を検索するパターンのタイプを選択する:
- 列の位置で検索するには、Index を選択する。
- ヘッダーをカンマ区切りで入力するには、Exact を選択する。
-
正規表現を使用するには、正規表現を選択します。
|
| マッチパターン |
結合する列の検索に使用するパターンまたはインデックスを入力します。 |
| 結合列ヘッダー |
結合から作成される新規列の名称を入力します。 |
| 結合テキスト |
- のように、新規列の値を結合するテキストを入力する。 |
| 破棄 |
新規作成のために結合した列を削除するには、このボックスをチェックする。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| 結合列出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
マップヘッダー
ヘッダーリストを別のヘッダーリストに置換するには、Map Headers コマンドを使用する。リストでは、ヘッダーをカンマで区切り、順番が重要である。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル の区切り文字を選択。 |
| 入力ヘッダー |
出力ヘッダー と同じ順序で、新規値に置換するヘッダーのリストを入力する。 |
| 出力ヘッダー |
入力ヘッダー と同じ順序で、出力に含む新規ヘッダーのリストを入力する。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
| インデックスを使用する |
入力ヘッダー が数値インデックスを使用する場合、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| マップヘッダー出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
ピボット
データ列の値を別々の列として表現するには、Pivot コマンドを使用します。列をピボットすると、その行の一意の値が新規列ヘッダーになります。
例えば、こんなデータがある:
YEAR,MEASURE,PRODUCT,MARKET,SCENARIO,Period,Amount FY20,Sales,100-10,Massachusetts,Actual,JAN,125 FY20,Sales,100-10,Massachusetts,Actual,FEB,225 FY20,Sales,100-10,Massachusetts,Actual,MAR,325 FY20,Sales,100-10,Massachusetts,Actual,APR,425 FY20,Sales,100-10,Massachusetts,Actual,MAY,525 FY20,Sales,100-10,Massachusetts,Actual,JUN,625 FY20,Sales,100-10,Massachusetts,Actual,JUL,725 FY20,Sales,100-10,Massachusetts,Actual,AUG,825 FY20,Sales,100-10,Massachusetts,Actual,SEP,925 FY20,Sales,100-10,Massachusetts,Actual,OCT,1025 FY20,Sales,100-10,Massachusetts,Actual,NOV,1125 FY20,Sales,100-10,Massachusetts,Actual,DEC,1225 FY20,COGS,100-10,Massachusetts,Actual,JAN,100 FY20,COGS,100-10,Massachusetts,Actual,FEB,200 FY20,COGS,100-10,Massachusetts,Actual,MAR,300 FY20,COGS,100-10,Massachusetts,Actual,APR,400 FY20,COGS,100-10,Massachusetts,Actual,MAY,500 FY20,COGS,100-10,Massachusetts,Actual,JUN,600 FY20,COGS,100-10,Massachusetts,Actual,JUL,700 FY20,COGS,100-10,Massachusetts,Actual,AUG,800 FY20,COGS,100-10,Massachusetts,Actual,SEP,900 FY20,COGS,100-10,Massachusetts,Actual,OCT,1000 FY20,COGS,100-10,Massachusetts,Actual,NOV,1100 FY20,COGS,100-10,Massachusetts,Actual,DEC,1200
MEASURE 列をピボットし、Amount 列を集計し、残りの列を行として指定すると、出力はMEASURE 列をそのSales およびCOGS 値の列に置換し、それぞれの金額を提供します:
YEAR,PRODUCT,MARKET,SCENARIO,Period,Sales,COGS FY20,100-10,Massachusetts,Actual,APR,425,400 FY20,100-10,Massachusetts,Actual,AUG,825,800 FY20,100-10,Massachusetts,Actual,DEC,1225,1200 FY20,100-10,Massachusetts,Actual,FEB,225,200 FY20,100-10,Massachusetts,Actual,JAN,125,100 FY20,100-10,Massachusetts,Actual,JUL,725,700 FY20,100-10,Massachusetts,Actual,JUN,625,600 FY20,100-10,Massachusetts,Actual,MAR,325,300 FY20,100-10,Massachusetts,Actual,MAY,525,500 FY20,100-10,Massachusetts,Actual,NOV,1125,1100 FY20,100-10,Massachusetts,Actual,OCT,1025,1000 FY20,100-10,Massachusetts,Actual,SEP,925,900
行から期間 列を除外すると、残りの行の各結合についてすべての期間が集計される:
年度,製品,市場,シナリオ,売上高,COGS 20年度,100-10,マサチューセッツ,実績,8100,7800
MEASUREと期間列の両方をピボットすると、それらの値の一意の結合がそれぞれ列として表示されます:売上-JAN, 売上-FEB, COGS-JANなどです:
YEAR,PRODUCT,MARKET,SCENARIO,Sales-JAN,Sales-FEB,Sales-MAR,Sales-APR,Sales-MAY,Sales-JUN,Sales-JUL,Sales-AUG,Sales-SEP,Sales-OCT,Sales-NOV,Sales-DEC,COGS-JAN,COGS-FEB,COGS-MAR,COGS-APR,COGS-MAY,COGS-JUN,COGS-JUL,COGS-AUG,COGS-SEP,COGS-OCT,COGS-NOV,COGS-DEC FY20,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225,100,200,300,400,500,600,700,800,900,1000,1100,1200
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
ピボットするデータのファイルを入力します。 |
| 区切り記号 |
入力ファイル のフィールドの区切りに使用するデリミタを選択する。 |
| 集計 |
ピボット値を集計する方法を選択します:
- SUM, 同じ行値を持つレコードを1つのレコードにまとめる。おすすめだ。
- NONE, 等価値の1つの設定に対して複数の行を作成する。ピボットされた列の各行には入力されますが、別の列にはNULLが含まれます。
|
| 集計する値 |
ピボットされた列の行に含むデータのある列を入力します。例えば、先ほどの例ではAmount 列のように入力します。 |
| ピボット列 |
列ヘッダーとして使用する行値の列を入力します。複数の列がある場合は、それぞれの値のユニークな結合ごとに別の列が表示される。 |
| 列の区切り文字 |
複数のピボット列、新規列ヘッダーで値を区切るために使用する区切り文字を入力します。 |
| ピボット列 |
入力ファイル に保持する列を入力する。出力では、これらの列の値のそれぞれのユニークな結合が行として表示される。集計する値またはピボット列と同じ列には、入力してはなりません。 |
| プレビュー結果 |
ピボット・データのプレビューを有効にするには、このボックスをチェックします。 |
出力
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
列の並び替え
DSVファイルの列を並べ替えるには、Reorder columns コマンドを使用する。列は名称やインデックスで識別できる。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| 列のオーダー |
入力ファイル の個々の列または範囲を、変換/トランスフォーメーションファイルに現れるべき順番で配列入力する。列を指定するには、1 で始まる名称またはインデックスを使用する。例えば、4:6 またはColA:ColC と入力して範囲を指定し、7 またはColH と入力して個別の列を指定する。 注: 列の順序に含まれない入力ファイル内の列は、変換列の最後に、入力ファイル と同じ順序で現れます。 |
| プレビュー結果 |
コマンド出力に結果のプレビュー(ヘッダーと最初の10行)を表示するには、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| 変換したファイル |
ファイル |
| 変換した行 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
スマートフィルター列
テキスト、日付、または数値に基づく複数のフィルターグループの条件をDSVファイルの行に適用するには、Smart Filter Rows コマンドを使用します。正規表現、または1つ以上の列の完全一致によって行を絞り込むことができます。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル で使用する区切り文字を選択する。 |
| インバース |
フィルター に一致する行をすべて削除せずに残すには、このボックスにチェックを入れる。 |
| フィルター |
入力ファイル に適用するテキスト、数字、日付フィルターを設定するには、フィルターグループの演算子(ANDまたはOR)を選択し、それぞれの条件を構成する。 テキスト フィルターグループの場合:
-
列名称 に、フィルターする列名称を入力する。
-
列名称 および比較テキスト の大文字小文字を無視するには、大文字小文字を区別しない を選択する。
-
条件 および比較テキスト に、「等しい [テキスト]」または「含む [テキスト]」のように、列を検索する値の条件を入力します。 <!--To apply
the inverse of the Condition
input, such as to match text that does not
equal or contain the Compare Text
input, select Not.-->
<!---
To remove any leading or trailing spaces from
matched text, select Trim.
-->
番号 フィルターグループの場合:
-
Format で、一致させる書式(整数または小数の桁数)を選択する。どちらでもよい場合は、小数の桁数を選択します。
-
列名称 に、フィルターする列名称を入力する。
-
条件 およびテスト番号 に、「[番号]と等しい」または「[番号]より小さい」など、列を検索する値の条件を入力する。 <!--To apply the inverse
of the Condition input,
such as to match numbers that do not
equal the Test Number input,
select Not.-->
<!---
To match numbers regardless of whether they're
positive or negative, select Absolute Value.
-->
日付 フィルターグループの場合:
-
書式設定 に、2006年1月2日を2006-01-02のように書式設定で入力します。
-
列名称 に、フィルターする列名称を入力する。
-
条件 と日付の比較 に、「[日付]と等しい」や「[日付]より小さい」など、列を検索する値の条件を入力する。 <!--To
apply the inverse of the Condition
input, such as to match dates that do not
equal the Compare Date
input, select Not.-->
|
| プレビュー結果 |
コマンド出力に結果のプレビューを表示するには、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| スマートフィルター行出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
ファイル分割
レコード数に基づいてファイルを複数のファイルに分割するには、Split File コマンドを使用する。例えば、以下のコマンドを使用して、より小さなチャンクを並列にプロセスすることで、パフォーマンスを向上させることができます。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
複数のファイルに分割するファイルを入力します。 |
| ファイル区切り記号 |
入力ファイル の各列の区切り文字を選択する。 |
| ヘッダーをプリペンドする |
作成された各ファイルチャンクに入力ファイル のヘッダーを含むには、このボックスにチェックを入れる。 |
| ファイルあたりのレコード数 |
各ファイルチャンクに含むレコードの最大数を入力します。 |
出力
| 出力 |
出力タイプ |
| ファイルチャンクの分割 |
ファイル |
| チャンク数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
ファイルチャンクの作成に失敗 |
分割値
値の区切り文字を指定して列を複数の列に分割するには、Split Value コマンドを使用する。
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
変換するファイルを入力します。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
入力ファイル で列の区切りに使用するデリミタを選択する。 |
| 新規ヘッダー |
分割値から作成する新規ヘッダーのリストを順番に入力します。 |
| 列名 |
分割する列のヘッダーを入力する。 |
| 値の区切り記号 |
値を分割する区切り文字を入力します。 |
| 破棄列 |
分割する列を削除するには、このボックスをチェックする。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| 分割値出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
スタックファイル
区切り文字で区切られた値(DSV)ファイルのリストの値を、指定された順序で積み重ねるには、Stack Files コマンドを使用する。新規ファイルでは、最初のファイルのヘッダー行が使われる。
メモ: このコマンドでファイルをスタックするには、すべてのファイルが同じ列数でなければならない。非対称 ファイルをスタックするには、 File Utils コネクター とそのStack Files コマンドを使用する。
プロパティ
| プロパティ |
詳細 |
| ファイル |
スタックするDSVファイルを入力する。 |
| 出力ファイル |
変換の結果ファイルの名称を入力します。 |
| 区切り記号 |
Files で列の区切りに使用する区切り文字を選択する。 |
| 入力ファイル |
スタックするファイルをコンマで区切って入力する。 メモ: ループを使用する場合、このフィールドは必須です(ファイルセクションにファイルがアップロードされないため)。このコマンドをFilesセクションに追加すると、"file not found "エラーが発生する。 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
出力
| 出力 |
出力タイプ |
| スタックファイル出力 |
ファイル |
| レコード数 |
整数 |
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
行/列の入れ替え
区切りファイルのすべてのフィールドを水平軸と垂直軸に沿って回転させ、行を列に、その逆を するには、Transpose コマンドを使用する。例えば、このコマンドで、このCSV:
id,1,2,3,4
name,"Johnson, Smith, and Jones Co.","Sam Smith",Barney & Co.,Johnson's Auto
amount,345.33,933.40,0,2344
remark,Pays on time,,"Great to work with.",
になる:
id,name,amount,remark
1,"Johnson, Smith, and Jones Co",345.33,Pays on time
2,"Sam Smith",933.40,
3,Barney & Co.,"Great to work with."
4,Johnson's Auto,2344,
プロパティ
| プロパティ |
詳細 |
| プレビュー結果 |
変換/トランスフォーメーション結果の最初の10行とヘッダーをプレビューするには、このボックスをチェックする。 |
| 入力ファイル |
転置する区切りファイルを入力します。 |
| ファイル区切り記号 |
入力ファイル の各列の区切り文字を選択する。 |
| チャンクサイズ |
処理する各作業ファイルの最大サイズをmb単位で入力する。 |
出力
| 出力 |
出力タイプ |
| 転置CSV |
ファイル |
| レコード数 |
整数 |
注: レコード数は、入れ替えたCSVの合計の行数を提供しますが、これにはヘッダー行は含まれません。
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
入力ファイルの転置に失敗しました。 |
アンピボット
財務データの期間など、複数列のデータを複数行の単一列に統合するには、Unpivot コマンドを使用する。例えば、こんなデータがある:
YEAR,MEASURE,PRODUCT,MARKET,SCENARIO,JAN,FEB,MAR,APR,MAY,JUN,JUL,AUG,SEP,OCT,NOV,DEC FY20,Sales,100-10,New York,Actual,100,200,300,400,500,600,700,800,900,1000,1100,1200 FY20,Sales,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225
毎月の金額を新規の期間 と金額 列にピボット解除できます:
YEAR,MEASURE,PRODUCT,MARKET,SCENARIO,Period,Amount FY20,Sales,100-10,Massachusetts,Actual,JAN,125 FY20,Sales,100-10,Massachusetts,Actual,FEB,225 FY20,Sales,100-10,Massachusetts,Actual,MAR,325 FY20,Sales,100-10,Massachusetts,Actual,APR,425 FY20,Sales,100-10,Massachusetts,Actual,MAY,525 FY20,Sales,100-10,Massachusetts,Actual,JUN,625 FY20,Sales,100-10,Massachusetts,Actual,JUL,725 FY20,Sales,100-10,Massachusetts,Actual,AUG,825 FY20,Sales,100-10,Massachusetts,Actual,SEP,925 FY20,Sales,100-10,Massachusetts,Actual,OCT,1025 FY20,Sales,100-10,Massachusetts,Actual,NOV,1125 FY20,Sales,100-10,Massachusetts,Actual,DEC,1225 FY20,Sales,100-10,New York,Actual,JAN,100 FY20,Sales,100-10,New York,Actual,FEB,200 FY20,Sales,100-10,New York,Actual,MAR,300 FY20,Sales,100-10,New York,Actual,APR,400 FY20,Sales,100-10,New York,Actual,MAY,500 FY20,Sales,100-10,New York,Actual,JUN,600 FY20,Sales,100-10,New York,Actual,JUL,700 FY20,Sales,100-10,New York,Actual,AUG,800 FY20,Sales,100-10,New York,Actual,SEP,900 FY20,Sales,100-10,New York,Actual,OCT,1000 FY20,Sales,100-10,New York,Actual,NOV,1100 FY20,Sales,100-10,New York,Actual,DEC,1200
プロパティ
| プロパティ |
詳細 |
| 入力ファイル |
ピボット解除するデータのファイルを入力します。 |
| 区切り記号 |
入力ファイル のフィールドの区切りに使用するデリミタを選択する。 |
| 集計 |
ピボットされていない値を集計する方法を選択します:
- SUM 、すべての列で値が同じ場合にレコードを集計する。おすすめだ。
- NONE、各レコードから一意のデータ値で複製行を作成します。
|
| 新規列ラベル |
ピボットされていない列に基づく行を持つ出力の列のヘッダーを入力する。先の例では、期間です。 |
| データ列ヘッダー |
ピボットされていない列のデータが出力される列のヘッダーを入力する。先の例では、量です。 |
| データヘッダー |
特定の 列のピボットを解除するには、その列のヘッダーをリストアップし、各列の間にEnter を押す。先の例では、JAN、FEB、MARなどです。 |
| ピボット開始列名称 |
ヘッダー による列の範囲 をピボット解除するには、範囲の最初の列の名称を入力する。先の例では、JAN 。 |
| ピボット列の名称 |
ヘッダー による列の範囲 をピボット解除するには、範囲の最後の列の名称を入力する。先の例では、DEC 。 注:ピボットの開始列名を入力するものの、ピボットの終了列名がない場合は、コマンドによってピボットが解除され、ピボットの開始列名の右側にあるすべての列がピボットされます。これは、ローリングフォーキャストで作成されたデータに有効である。 |
| ピボット列の開始インデックス |
範囲 の列を位置 でピボット解除するには、範囲の最初の列のインデックス値を入力する。入力ファイル の列が 0 から始まる、ゼロベースのインデックスを使用する。先の例では、5 。 |
| ピボット列のインデックスを終了します。 |
範囲 の列を位置 でピボット解除するには、範囲の最後の列のインデックス値を入力する。入力ファイル の列が 0 から始まる、ゼロベースのインデックスを使用する。先の例では、16 。 注:ピボットの開始列索引を入力するものの、ピボットの終了列索引がない場合は、コマンドによってピボットが解除され、ピボットの開始列索引の右側にあるすべての列がピボットされます。これは、ローリングフォーキャストで作成されたデータに有効である。 |
| プレビュー結果 |
ピボットされていない出力のプレビューを有効にするには、このボックスをチェックします。 |
出力
閉じるコード
| コード |
タイプ |
詳細 |
| 0 |
成功 |
成功 |
| 1 |
エラー |
無効な引数 |
| 2 |
エラー |
一般的な失敗 |
| 14 |
エラー |
無効な出力ファイルの場所 |
| 15 |
エラー |
入力ファイルで使用されるエスケープ文字で、通常は" |
トラブルシューティング
コマンドに失敗した場合は、以下の一般的な問題をチェックしてください。
誤った区切り文字
変換の構成時に間違った区切り文字が設定されると、変換は期待通りに実行されません。
適切なCSVではない
表形式のデータセットが適切なCSVでない場合、変換/トランスフォーメーションコマンドは実行されない。入力をプロセスする前に、書式設定がRFC 4180に準拠しているかどうかをチェックするからだ。適切なCSV:
- ASCII、Unicode(UTF-8など)、EBCDIC、シフトJISなどの文字設定を使用したプレーンテキストでデータを格納します。
- 1行1レコードのレコードと、区切り文字(通常はカンマ、セミコロン、タブなどの予約文字1文字)で区切られたフィールドに分けられたレコードから構成される。区切り文字にオプションの間隔を含むこともあります。
-
すべてのレコードに同じ一連のフィールドがある
- 通常、フラットファイルまたはリレーショナルデータのレポート出力
各レコードの列数の不一致
表データセットのレコードの列数が異なる場合、変換コマンドはそれが適切なCSVでないことを検出します。
列数の違い
列数の異なる2つの適切なCSV表データセットを結合してもうまくいかず、Stack Filesコマンドはエラーを表示します。