Per preparare i dati DSV (delimiter-separated values) per il caricamento, ad esempio per massaggiare i dati tabellari nel formato richiesto, aggiungi un passo in una catena che utilizza un comando di connessione di trasformazione tabellare. Ad esempio:
- Dividere i set di dati in base al contenuto di un record
- Filtrare in base a regole
- Combinare set di dati da più fonti
Per attivare questi comandi, un amministratore IT deve prima creare un connettore di trasformazione tabellare.
Aggiungi intestazione
Per aggiungere una riga di intestazione a un file CSV (comma-separated values), usa il comando Add Header.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file a cui aggiungere le intestazioni. |
| Delimitatore |
Seleziona il delimitatore utilizzato per separare le colonne in File di input. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
| Riga di intestazione |
Inserisci l'intero contenuto della riga di intestazione. Separa ogni intestazione con un delimitatore, ad esempio Colonna1,Colonna2,Colonna3. |
| Delimitatore dell'intestazione |
Inserisci il delimitatore utilizzato per separare le intestazioni in Riga di intestazione, come ad esempio , |
Output
| Output |
Tipo di output |
| CSV con intestazioni |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
Aggiungi numeri di riga
Per aggiungere il numero di riga al DSV nella prima colonna, usa il comando Add Row Numbers.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file a cui aggiungere i numeri di riga. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Inserisci il delimitatore utilizzato per separare le colonne in File di input. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Aggiungi numeri di riga in uscita |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Query avanzata
Per eseguire una query SQL su uno o più file CSV, usa il comando Advanced Query. Puoi anche unire altri file allegati a questo comando.
Nota: Questo comando supporta le istruzioni SELECT e le istruzioni complementari JOIN, ma non le istruzioni come INSERT, UPDATE, o CREATE. Per inserire delle righe, usa il comando Stack Files; per aggiornare le righe, Find and Replace.
Proprietà
| Proprietà |
Dettaglio |
| Tabelle |
Inserisci tutti i file da utilizzare nella query e il nome della loro tabella. |
| Query |
Inserisci la query SQL da eseguire, come sintassi SQLite:
- Se i nomi delle colonne o gli identificatori contengono spazi o caratteri speciali, usa le parentesi. Ad esempio,
[Colonna A], [Colonna B].
- Per formattare i dati con due spazi decimali, usa la sintassi
SELECT PRINTF('%.2f',(SUM(DATA)) COME EBITDA FROM HFMDat.
- Per selezionare la prima istanza di un duplicato, ad esempio se due record hanno lo stesso
ID, usa la sintassi select * from group by ID having MIN(ID) ORDER BY ID.
- Per concatenare più stringhe insieme, usa l'operatore
|| come string1 || string2 [ || string_n ].
|
| Delimitatore input |
Seleziona il delimitatore utilizzato nelle tabelle e nei file di join. |
| Delimitatore output |
Seleziona il delimitatore da utilizzare nei risultati della query. |
| Anteprima |
Per stampare un'anteprima dei risultati della query, seleziona questa casella. |
Il comando Advanced Query cerca automaticamente di determinare il tipo di dati di una colonna. Per mantenere gli zeri iniziali di un valore che il comando sbaglia per un numero intero, usa i comandi Trova e Sostituisci con Regex e Sostituisci solo le corrispondenze selezionate per aggiungere apici singoli (') intorno ai valori della colonna e poi rimuoverli al termine del comando Advanced Query:
- Per aggiungere le virgolette singole, trova
(\d+), e sostituisci con '$1'.
- Per rimuovere le virgolette singole, trova
'(\d+)' e sostituiscilo con $1.
Con Regex selezionato, il comando Find and Replace utilizza le parentesi (()) per catturare il gruppo o i caratteri e poi li sostituisce come primo parametro $1. Per creare catture multiple, utilizza serie successive di parentesi e valori incrementali come $2.
Output
| Output |
Tipo di output |
| Risultato |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Cambia delimitatore
Per cambiare il delimitatore di un file CSV, usa il comando Change Delimiter.
Nota: Per rispettare le specifiche RFC, utilizza sempre un singolo carattere come delimitatore, preferibilmente una virgola o un carattere di tabulazione.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| Delimitatore input |
Inserisci il delimitatore attualmente utilizzato nel file di input . Per un carattere di tabulazione, inserisci \t. |
| Delimitatore output |
Inserisci il delimitatore da utilizzare dopo la trasformazione. Per un carattere di tabulazione, inserisci \t. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
| Mantieni le righe vuote |
Seleziona questa casella per mantenere le righe vuote nell'output. Vengono rimosse per impostazione predefinita. |
Output
| Output |
Tipo di output |
| Risultato CSV |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
Pulire i newline non quotati
Per tentare di pulire un file conforme alla Request for Comments (RFC), tranne che per i caratteri di nuova riga non quotati, usa il comando Clean Unquoted Newlines. Ad esempio, usa questo comando per elaborare file di dati con caratteri non coerenti per i ritorni a capo o le nuove righe.
Nota: Questo comando pulisce solo le nuove righe non quotate. Altri problemi non conformi causeranno comunque il fallimento del set di dati.
Proprietà
| Proprietà |
Dettaglio |
| Anteprima del risultato |
Per visualizzare l'anteprima del risultato nel registro del comando, seleziona questa casella. |
| File di input |
Inserisci il file da pulire. |
| Delimitatore del file |
Seleziona il delimitatore per ogni colonna in File di input. |
| Usa le virgolette pigre |
Per consentire alle virgolette di apparire nei campi non quotati e alle virgolette non doppie di apparire nei campi quotati, seleziona questa casella. |
| Aggiungi testo a capo |
Per aggiungere le righe di una sola colonna senza delimitatori nel file di input all'ultimo valore dell'ultima colonna del record precedente, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Output newlines pulite |
File |
| Conteggio delle linee |
Numero intero |
Nota: L'output Conteggio delle righe fornisce il numero totale di record, compresa l'intestazione, nell'output Linee nuove pulite.
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Impossibile creare l'output newline pulite |
Filtro colonne
Per filtrare le colonne DSV con intestazioni che corrispondono allo schema specificato, usa il comando Column Filter.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Tipo di modello |
Seleziona il tipo di modello per cui filtrare:
-
Indice per filtrare in base all'indice della colonna
-
Exact per filtrare in base a un elenco di valori esatti separati da una virgola
-
Regex per filtrare con un'espressione regolare
|
| Schema |
Inserisci il modello con cui abbinare le colonne. Se Il tipo di modello è Indice, applica l'operatore di diffusione, ad esempio 1:5,7:8,10:15. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
| Inverso |
Per mantenere le colonne corrispondenti e rimuovere tutte le altre, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Uscita del filtro delle colonne |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Concat file
Per unire più file sorgente di dati tabellari orizzontalmente in un unico set di dati CSV, usa il comando Concat Files.
Proprietà
| Proprietà |
Dettaglio |
| File sorgente |
Inserisci i file da concatenare. |
| Anteprima del risultato |
Per visualizzare l'anteprima del risultato nel registro del comando, seleziona questa casella. |
| Delimitatore di file |
Seleziona il delimitatore utilizzato in File sorgente. |
Output
| Output |
Tipo di output |
| CSV unito |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Non è riuscito a generare CSV |
Convertire CSV in XLSX
Per convertire un file CSV in una cartella di lavoro di Microsoft Excel® (XLSX), usa il comando Convert CSV to XLSX.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da convertire in XLSX. |
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Nome del foglio |
Inserisci il nome del foglio da creare nella cartella di lavoro di Excel. |
| File di output |
Inserisci il percorso in cui memorizzare il file (opzionale). Se viene utilizzato come output per un altro comando della catena, lascia vuoto. |
Output
| Output |
Tipo di output |
| Uscita XLSX |
File |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
Convertire JSON in CSV
Per convertire un file JSON in CSV, usa il comando Convert JSON to CSV.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file JSON da convertire in CSV. |
| File di output |
Inserisci il percorso in cui salvare il nuovo file CSV. Se la usi come output per un altro comando della catena, lascia in bianco. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Uscita CSV |
File |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
Convertire in tabelle incrociate
Per convertire un set di dati tabellari, ad esempio l'output di una query Oracle Essbase® multidimensional expressions (MDX), in un formato di tabulazione incrociata, o crosstab, usa il comando Convert to Cross-Tab. Questo comando basa il layout della tabella incrociata sulle intestazioni delle colonne e delle righe definite come tuple nel set di dati tabellari di input.
Ad esempio, con questo comando, questo set di dati:
(Misure, Prodotto, Mercato) (Effettivo, Trimestre1) (Effettivo, Trimestre2) (Effettivo, Trimestre3) (Effettivo, Trimestre4) (Budget, Trimestre1) (Budget, Trimestre2) (Budget, Trimestre3) (Budget, Trimestre4) (Vendite, 100-10, New York) 1995.0 2358,0 2612,0 1972,0 2249,0 2220,0 2470,0 1720,0 (Vendite, 100-10, Massachusetts) 1456,0 1719,0 1905,0 1438,0 1360,0 1620,0 1800,0 1250,0 (Vendite, 100-10, Florida) 620,0 735.0 821,0 623,0 570,0 690,0 770,0 530,0 (Vendite, 100-10, Connecticut) 944,0 799,0 708,0 927,0 880,0 750,0 660,0 810,0 (Vendite, 100-10, New Hampshire) 353,0 413,0 459,0 345,0 320.0 370,0 430,0 280,0 (Vendite, 100-10, California) 1998,0 2358,0 2612,0 1972,0 2480,0 2940,0 3250,0 2530,0 (Vendite, 100-10, Oregon) 464,0 347,0 345,0 370,0 570,0 420,0 420,0 470,0
può diventare una tabella incrociata delimitata da tabelle:
Effettivo Effettivo Effettivo Budget Budget Budget Qtr1 Qtr2 Qtr3 Qtr4 Qtr1 Qtr2 Qtr3 Qtr4 Vendite 100-10 New York 1995,0 2358,0 2612,0 1972,0 2249,0 2220.0 2470.0 1720.0 Vendite 100-10 Massachusetts 1456.0 1719.0 1905.0 1438.0 1360.0 1620.0 1800.0 1250.0 Vendite 100-10 Florida 620.0 735.0 821.0 623.0 570.0 690.0 770.0 530.0 Vendite 100-10 Connecticut 944.0 799.0 708.0 927.0 880.0 750.0 660.0 810.0 Vendite 100-10 New Hampshire 353.0 413.0 459.0 345.0 320.0 370.0 430.0 280,0 Vendite 100-10 California 1998,0 2358,0 2612,0 1972,0 2480,0 2940,0 3250,0 2530,0 Vendite 100-10 Oregon 464,0 347,0 345,0 370,0 570,0 420,0 420,0 470,0
Sampia configurazione
La configurazione sarà simile a questa:
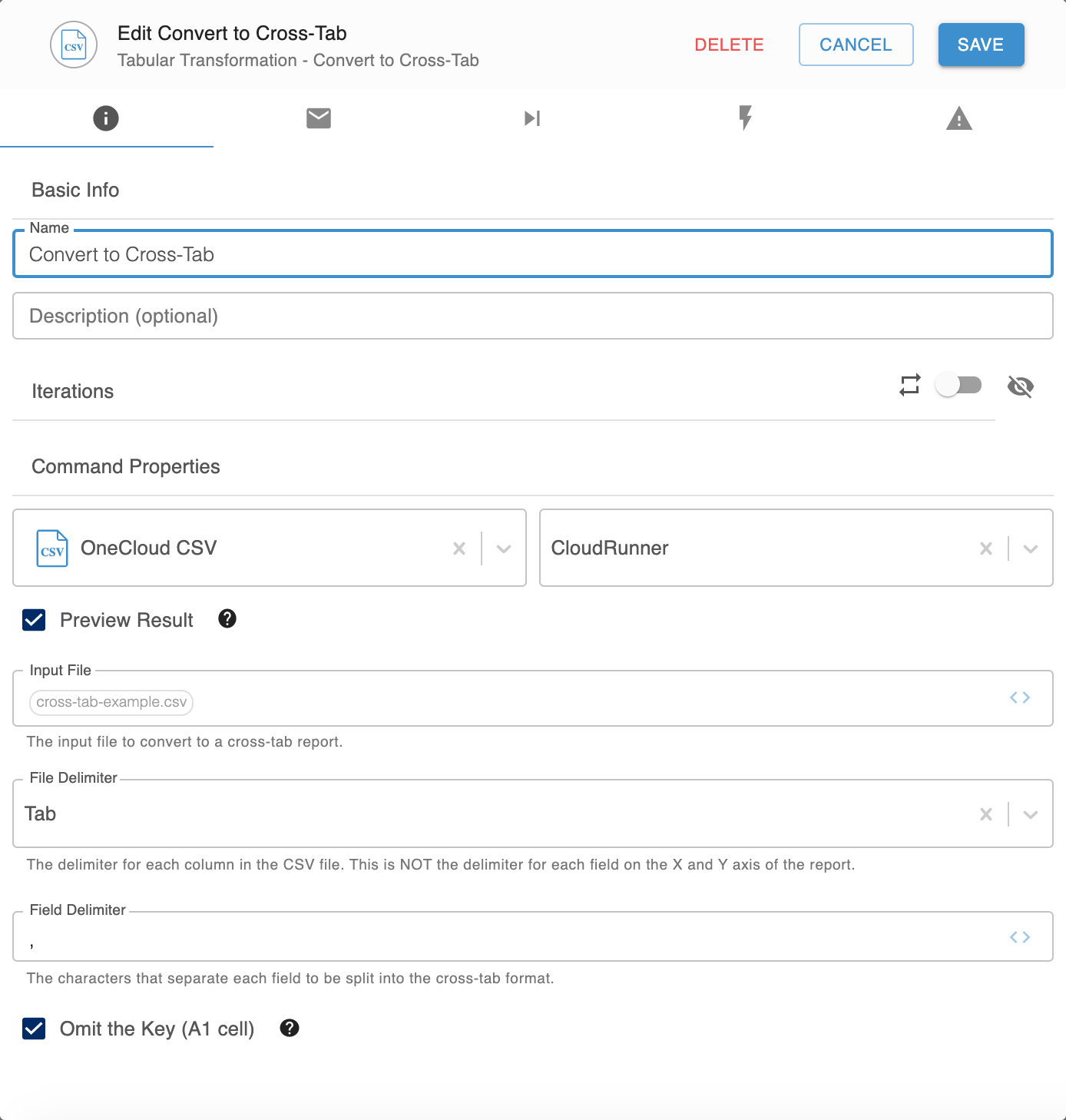
Proprietà
| Proprietà |
Dettaglio |
| Anteprima del risultato |
Per visualizzare l'anteprima del formato crosstab, seleziona questa casella. |
| File di input |
Inserisci il file da convertire in un formato crosstab, con le intestazioni delle colonne e delle righe definite come tuple. Nota: Imposta il file di input in modo che la prima colonna sia un insieme delimitato di valori da diffondere orizzontalmente e la prima riga sia un insieme delimitato di valori da diffondere verticalmente. |
| Delimitatore del file |
Seleziona il delimitatore utilizzato con le colonne in File di input. |
| Delimitatore di campo |
Inserisci il carattere da utilizzare per separare ogni campo suddiviso nel formato crosstab. |
| Ometti la chiave (cella A1) |
Per omettere la cella A1 del file di input dal formato crosstab, seleziona questa casella. Ad esempio, se la cella A1 contiene (A,B), le celle A1 e A2 del formato tabulato incrociato sono vuote; in caso contrario, contengono A e B. |
Output
| Output |
Tipo di output |
| Rapporto a schede incrociate |
File |
| Conteggio delle linee |
Numero intero |
Nota: L'output Conteggio linee fornisce il numero totale di righe nel report Crosstab, incluse tutte le righe di intestazione.
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
Convertire XLSX in CSV
La versione della trasformazione tabellare di questo comando non è più disponibile. Tutte le catene esistenti che utilizzano questo comando continueranno a funzionare, ma non potranno essere create istanze future.
Si consiglia invece di utilizzare il comando Worksheet to CSV del connettore Excel.
Copia colonna
Per copiare una colonna da un file DSV, usa il comando Copy Column.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Nome della colonna |
Inserisci il nome della colonna da copiare. |
| Nome della nuova colonna |
Inserisci il nome della copia risultante della colonna. |
| Inserisci indice |
Inserisci l'indice della colonna in cui inserire la copia della colonna. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Copia l'output della colonna |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato nel file di input, di solito un " |
Estrai valore
Per estrarre un valore da un file DSV in base all'indice di riga e all'indice di colonna, usa il comando Extract Value.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Indice di riga |
Inserisci il numero di riga da cui estrarre il valore; la prima riga del file di input è 1. |
| Indice colonna |
Inserisci il numero di colonna dell'indice di riga da cui estrarre il valore. Per estrarre l'intera riga, lascia vuoto. |
Output
| Output |
Tipo di output |
| Riga |
JSON |
| Valore |
Stringa |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
Filtrare le righe
Per filtrare le righe del DSV in base a un'espressione regolare (regex) o a una corrispondenza esatta di una o più colonne della riga, usa il comando Filter Rows.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Modello di ricerca |
Inserisci il modello da utilizzare per trovare le corrispondenze. |
| Tipo di modello di corrispondenza |
Seleziona se abbinare un modello Regex o Exact. |
| Insensibile alle maiuscole |
Per ignorare le maiuscole del testo, seleziona questa casella. |
| Inverso |
Per mantenere tutte le righe corrispondenti e scartare le altre, seleziona questa casella. |
| Colonne di ricerca |
Inserisci un elenco separato da virgole di indici di colonne a cui limitare la ricerca. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella |
Nota: Il comando Filter Rows si aspetta un file DSV corretto con intestazioni. Per filtrare la prima riga di un file senza intestazioni, usa il comando Find di una connessione a File Utilities.
Output
| Output |
Tipo di output |
| Filtrare l'output della riga |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato nel File di input, di solito un " |
Trova e sostituisci
Per trovare e sostituire i valori delle colonne nei dati in base a un'espressione regolare , a una stringa di testo completo o a un indice di colonna, usa il comando Find and Replace.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Specifica se produrre il file originale o una copia:
- Per produrre il file originale con i valori aggiornati delle colonne, inserisci lo stesso file di File di input.
- Per ottenere una copia dell'originale con i valori aggiornati delle colonne, inserisci il nome del nuovo file.
|
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Modello di ricerca |
Inserisci l'espressione regolare, la stringa di testo o l'indice di colonna da utilizzare per identificare i valori da sostituire, in base a Tipo di modello di corrispondenza. |
| Tipo di modello di corrispondenza |
Seleziona come identificare i valori della colonna da trovare:
- Per trovare i valori basati su un'espressione regolare, seleziona
Regex.
- Per trovare i valori che corrispondono a una stringa di testo completo, seleziona
Exact.
- Per trovare i valori in base alla loro colonna, seleziona
Indice.
Nota: Exact corrisponde alla stringa completa di ogni colonna. Per trovare e sostituire un valore parziale con una colonna, seleziona Regex e Solo le corrispondenze di sostituzione. |
| Valore di sostituzione |
Inserisci il testo con cui sostituire i valori corrispondenti. Nota: Se Il tipo di modello di corrispondenza è Indice, il valore sostitutivo sostituisce tutti i valori della colonna abbinata. |
| Insensibile alle maiuscole |
Per ignorare le maiuscole del testo, seleziona questa casella. |
| Sostituisci solo le corrispondenze |
Se Il tipo di modello di corrispondenza è Regex, seleziona questa casella per sostituire solo il testo corrispondente con il valore di sostituzione. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
| Colonne |
Inserisci un elenco separato da virgole di colonne a cui applicare il comando, con 0 per la prima colonna. Ad esempio, 0,1,2,3 limita il comando alle prime quattro colonne. |
Nota: Per applicare lo stesso Valore sostitutivo input a più valori, usa un'espressione regolare come Find Pattern input, ad esempio (?:Varianza|Varianza %|Tutti i periodi|FY15|YTD).
Output
| Output |
Tipo di output |
| Trova e sostituisci l'output |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in Input File, di solito un ". |
Inserire colonna
Per inserire una colonna in un file DSV, usa il comando Insert Column.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Testo dell'intestazione |
Inserisci il nome dell'intestazione della nuova colonna. |
| Valore dei dati |
Inserisci il testo da inserire nella nuova colonna. |
| Inserisci indice |
Inserisci l'indice della colonna in cui inserire la nuova colonna. |
| Anteprima dei risultati |
Per visualizzare un'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
Nota: Per inserire più colonne aggiungi una colonna al file di input con un'intestazione EMPTY_REPLACED_HEADER, con un valore per ogni riga EMPTY_REPLACED_VALUE. Con la connessione a File Utilities, usa i comandi Find and Replace per sostituire il segnaposto dell'intestazione con l'intestazione della colonna desiderata e il segnaposto del valore con una stringa del numero di virgole necessarie.
Output
| Output |
Tipo di output |
| Inserisci l'output della colonna |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Unisci colonne
Per unire più colonne di un file DSV e scartare le colonne utilizzate, usa il comando Join Columns.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore di File di input. |
| Indice della colonna unita |
Inserisci l'indice numerico della nuova colonna. Per la prima colonna, inserisci 0. |
| Tipo di modello di ricerca |
Seleziona il tipo di modello per cui cercare le colonne:
- Per cercare per posizione delle colonne, seleziona Indice.
- Per inserire un elenco di intestazioni separate da virgole, seleziona Exact.
- Per utilizzare l'espressione regolare , seleziona Regex.
|
| Schema di corrispondenza |
Inserisci il modello o l'indice da utilizzare per trovare le colonne da unire. |
| Intestazione della colonna unita |
Inserisci il nome della nuova colonna creata dall'unione. |
| Testo di unione |
Inserisci il testo che unisce i valori nella nuova colonna, ad esempio -. |
| Rimuovere |
Per rimuovere le colonne unite per creare la nuova colonna, seleziona questa casella. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime 10 righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Unisci l'output della colonna |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Mappa intestazioni
Per sostituire un elenco di intestazioni con un altro elenco di intestazioni, usa il comando Map Headers. Negli elenchi, i titoli devono essere separati da virgole e l'ordine è importante.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore di File di input. |
| Intestazioni di input |
Inserisci un elenco di intestazioni da sostituire con nuovi valori, nello stesso ordine di Intestazioni di output. |
| Intestazioni output |
Inserisci un elenco delle nuove intestazioni da includere nell'output, nello stesso ordine di Intestazioni di input. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
| Usa gli indici |
Se L'intestazione di input utilizza indici numerici, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Intestazioni della mappa in uscita |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Pivot
Per rappresentare i valori di una colonna di dati come colonne separate, usa il comando Pivot. Quando fai un pivot su una colonna, i valori unici delle sue righe diventano nuove intestazioni di colonna.
Ad esempio, dati questi dati:
ANNO,MISURA,PRODOTTO,MERCATO,SCENARIO,Periodo,Importo FY20,Vendite,100-10,Massachusetts,effettivo,GEN,125 FY20,Vendite,100-10,Massachusetts,effettivo,FEB,225 FY20,Vendite,100-10,Massachusetts,effettive,MAR,325 FY20,Vendite,100-10,Massachusetts,effettive,APR,425 FY20,Vendite,100-10,Massachusetts,effettive,MAGGIO,525 FY20,Vendite,100-10,Massachusetts,effettivo,GIUGNO,625 FY20,Vendite,100-10,Massachusetts,effettivo,LUGLIO,725 FY20,Vendite,100-10,Massachusetts,effettivo,AGOSTO,825 FY20,Vendite,100-10,Massachusetts,effettivo,SET,925 FY20,Vendite,100-10,Massachusetts,effettivo,OTTO,1025 FY20,Vendite,100-10,Massachusetts,effettivo,NOV,1125 FY20,Vendite,100-10,Massachusetts,effettivo,DIC,1225 FY20,COGS,100-10,Massachusetts,effettivo,GEN,100 FY20,COGS,100-10,Massachusetts,effettivo,FEB,200 FY20,COGS,100-10,Massachusetts,effettivo,MAR,300 FY20,COGS,100-10,Massachusetts,effettivo,APR,400 FY20,COGS,100-10,Massachusetts,effettivo,MAGGIO,500 FY20,COGS,100-10,Massachusetts,GIUGNO,600 Esercizio 20,COGS,100-10,Massachusetts,effettivo,LUGLIO,700 Esercizio 20,COGS,100-10,Massachusetts,effettivo,AGOSTO,800 Esercizio 20,COGS,100-10,Massachusetts,effettivo,SEP,900 FY20,COGS,100-10,Massachusetts,effettivo,OTTO,1000 FY20,COGS,100-10,Massachusetts,effettivo,NOV,1100 FY20,COGS,100-10,Massachusetts,effettivo,DIC,1200
Se fai una pivot sulla colonna MISURA, aggreghi la colonna Importo e specifichi le colonne rimanenti come righe, l'output sostituisce la colonna MISURA con le colonne per i valori Vendite e COGS e fornisce i rispettivi importi:
ANNO,PRODOTTO,MERCATO,SCENARIO,Periodo,Vendite,COGS FY20,100-10,Massachusetts,Effettivo,APR,425,400 FY20,100-10,Massachusetts,Effettivo,AUG,825,800 FY20,100-10,Massachusetts,Actual,DEC,1225,1200 FY20,100-10,Massachusetts,Actual,FEB,225,200 FY20,100-10,Massachusetts,Actual,JAN,125,100 FY20,100-10,Massachusetts,Actual,JUL,725,700 FY20,100-10,Massachusetts,Actual,JUN,625,600 FY20,100-10,Massachusetts,Actual,MAR,325,300 FY20,100-10,Massachusetts,Actual,MAY,525,500 FY20,100-10,Massachusetts,Actual,NOV,1125,1100 FY20,100-10,Massachusetts,Actual,OCT,1025,1000 FY20,100-10,Massachusetts,Actual,SEP,925,900
Se escludi la colonna Period dalle righe, tutti i periodi di tempo si aggregano per ogni combinazione delle righe rimanenti:
ANNO,PRODOTTO,MERCATO,SCENARIO,VENDITE,COGS FY20,100-10,Massachusetts,effettivo,8100,7800
Se fai una pivot su entrambe le colonne MISURA e Periodo, ogni combinazione unica dei loro valori appare come colonne, come Vendite-GEN, Vendite-FEB, COGS-GEN, e così via:
ANNO,PRODOTTO,MERCATO,SCENARIO,Vendite-GENNA,Vendite-FEB,Vendite-MAR,Vendite-APR,Vendite-MAGGIO,Vendite-GIU,Vendite-LUGLIO,Vendite-AUG,Vendite-SEP,Vendite-PT,Vendite-NOV,Vendite-DIC,COGS-GENNA,COGS-FEB,COGS-MAR,COGS-APR,COGS-MAY,COGS-JUN,COGS-JUL,COGS-AUG,COGS-SEP,COGS-OCT,COGS-NOV,COGS-DEC FY20,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225,100,200,300,400,500,600,700,800,900,1000,1100,1200
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file con i dati da inserire nel pivot. |
| Delimitatore |
Seleziona il delimitatore utilizzato per separare i campi in File di input. |
| Aggregazione |
Seleziona come aggregare i valori pivotati:
- SOMMA, per raggruppare i record con gli stessi valori di riga in un unico record. Consigliato.
- NONE, per creare più righe per un singolo insieme di valori equivalenti. Ogni riga della colonna imperniata sarà popolata, ma le altre possono includere NULL.
|
| Valori da aggregare |
Inserisci la colonna con i dati da includere nelle righe delle colonne pivotate, come ad esempio la colonna Importo nell'esempio precedente. |
| Colonne pivot |
Inserisci le colonne con i valori delle righe da utilizzare come intestazioni di colonna. Se le colonne sono multiple, viene visualizzata una colonna separata per ogni combinazione unica dei loro valori. |
| Delimitatore di colonna |
Se più colonne Pivot, inserisci il delimitatore da utilizzare per separare i loro valori nelle nuove intestazioni di colonna. |
| Righe pivot |
Inserisci le colonne in File di input da conservare. Nell'output, ogni combinazione unica dei valori di queste colonne appare come righe. Non non inserire le stesse colonne di Valori da aggregare o Colonne pivot. |
| Anteprima dei risultati |
Per abilitare l'anteprima dei dati con il pivot, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Risultato con pivot |
File |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Riordina colonne
Per riordinare le colonne di un file DSV, usa il comando Riordina colonne. Puoi identificare le colonne in base al loro nome o all'indice.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Ordini delle colonne |
Inserisci un array di singole colonne o intervalli dal file di input , nell'ordine in cui devono apparire nel file trasformato. Per specificare le colonne, usa il loro nome o il loro indice, a partire da 1. Ad esempio, inserisci 4:6 o ColA:ColC per specificare un intervallo, oppure 7 o ColH per una singola colonna. Nota: Qualsiasi colonna di File di input non inclusa in Gli ordini di colonna appaiono alla fine delle colonne del file trasformato, nello stesso ordine di File di input. |
| Anteprima dei risultati |
Per visualizzare un'anteprima dei risultati - l'intestazione e le prime 10 righe - nell'output del comando, seleziona questa casella. |
Output
| Output |
Tipo di output |
| File trasformato |
File |
| Righe trasformate |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
Filtro intelligente righe
Per applicare i criteri di più gruppi di filtri basati su valori di testo, data o numero alle righe di un file DSV, usa il comando Smart Filter Rows. Puoi filtrare le righe in base all'espressione regolare o a una corrispondenza esatta di una o più colonne.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore utilizzato in File di input. |
| Inverso |
Per mantenere, anziché rimuovere, tutte le righe che corrispondono ai filtri , seleziona questa casella. |
| Filtri |
Per impostare i filtri di testo, numero o data da applicare a File di input, seleziona l'operatore per i gruppi di filtri - AND o OR - e configura i criteri per ciascuno di essi. Per un gruppo di filtri text:
- In Column Name, inserisci il nome della colonna da filtrare.
- Per ignorare le caselle di Nome colonna e Testo di confronto, seleziona Insensibile alle caselle.
- In Condizione e Testo di confronto, inserisci i criteri del valore da cercare nella colonna, ad esempio "Uguale a [testo]" o "Contiene [testo]". <!--To apply
the inverse of the Condition
input, such as to match text that does not
equal or contain the Compare Text
input, select Not.-->
<!---
To remove any leading or trailing spaces from
matched text, select Trim.
-->
Per un numero gruppo di filtri:
- In Formato, seleziona il formato del numero da abbinare: intero o decimale. Se può essere uno dei due, seleziona Decimale.
- In Nome colonna, inserisci il nome della colonna da filtrare.
- In Condizione e Numero di prova, inserisci i criteri del valore da ricercare nella colonna, ad esempio "Uguale a [numero]" o "Inferiore a [numero]". <!--To apply the inverse
of the Condition input,
such as to match numbers that do not
equal the Test Number input,
select Not.-->
<!---
To match numbers regardless of whether they're
positive or negative, select Absolute Value.
-->
Per un gruppo di filtri date:
- In Format, inserisci January 2, 2006 nel formato della data da abbinare, ad esempio 2006-01-02.
- In Nome colonna, inserisci il nome della colonna da filtrare.
- In Condition e Compare Date, inserisci i criteri del valore da cercare nella colonna, ad esempio "Equals [date]" o "Less than [date]". <!--To
apply the inverse of the Condition
input, such as to match dates that do not
equal the Compare Date
input, select Not.-->
|
| Anteprima dei risultati |
Per visualizzare un'anteprima dei risultati nell'output del comando, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Uscita riga del filtro intelligente |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Dividi file
Per dividere un file in più file in base al numero di record, usa il comando Split File. Ad esempio, usa questo comando per elaborare pezzi più piccoli in parallelo per migliorare le prestazioni.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da dividere in più file. |
| Delimitatore di file |
Seleziona il delimitatore per ogni colonna in File di input. |
| Prependi intestazione |
Per includere l'intestazione di Il file di input in ogni pacchetto di file creato, seleziona questa casella. |
| Record per file |
Immetti il numero massimo di record da includere in ogni file chunk. |
Output
| Output |
Tipo di output |
| Dividere i pezzi di file |
File |
| Numero di pezzi |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Impossibile creare i file chunks |
Dividi valore
Per dividere una colonna in più colonne con un delimitatore di valore, usa il comando Split Value.
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file da trasformare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore utilizzato per separare le colonne in File di input. |
| Nuove intestazioni |
Inserisci un elenco di nuove intestazioni da creare a partire dal valore di divisione, in ordine. |
| Nome della colonna |
Inserisci l'intestazione della colonna da dividere. |
| Delimitatore del valore |
Inserisci il delimitatore su cui dividere il valore. |
| Scarta la colonna |
Per rimuovere la colonna che si sta dividendo, seleziona questa casella. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Uscita valori divisi |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un " |
Impilare i file
Per impilare i valori di un elenco di file di valori separati da delimitatori (DSV) uno sopra l'altro in un ordine specifico, usa il comando Stack Files. La riga di intestazione del primo file sarà utilizzata nel nuovo file.
Nota: Per impilare i file con questo comando, devono avere tutti lo stesso numero di colonne. Per impilare i file asimmetrici, usa il connettore File Utils e il comando Stack Files.
Proprietà
| Proprietà |
Dettaglio |
| File |
Inserisci i file DSV da impilare. |
| File di output |
Inserisci il nome del file risultante della trasformazione. |
| Delimitatore |
Seleziona il delimitatore utilizzato per separare le colonne in File. |
| File di input |
Inserisci i file da impilare, separati da una virgola. Nota: Quando si utilizza un ciclo, questo campo è obbligatorio (perché i file non vengono caricati nella sezione File). Il comando genera un errore di "file non trovato" se viene aggiunto alla sezione File. |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
Output
| Output |
Tipo di output |
| File di stack in uscita |
File |
| Conteggio dei record |
Numero intero |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, solitamente un " |
Trasposizione
Per ruotare tutti i campi di un file delimitato lungo l'asse orizzontale e verticale, in modo che le righe diventino colonne e viceversa, usa il comando Transpose. Ad esempio, con questo comando, questo CSV:
id,1,2,3,4
nome, "Johnson, Smith, and Jones Co.", "Sam Smith",Barney & Co.,Johnson's Auto
importo,345.33,933.40,0,2344
commento,Paga puntualmente, "Ottimo lavoro",
diventa:
id,name,amount,remark
1, "Johnson, Smith, and Jones Co",345.33,Paga puntualmente
2, "Sam Smith",933.40,
3,Barney & Co., "Ottimo lavoro"
4,Johnson's Auto,2344,
Proprietà
| Proprietà |
Dettaglio |
| Anteprima dei risultati |
Per visualizzare l'anteprima delle prime dieci righe e dell'intestazione dei risultati della trasformazione, seleziona questa casella. |
| File di input |
Inserisci il file delimitato da trasporre. |
| Delimitatore del file |
Seleziona il delimitatore di ogni colonna di File di input. |
| Dimensione del pezzo |
Inserisci la dimensione massima in mb di ogni file di lavoro da elaborare. |
Output
| Output |
Tipo di output |
| CSV trasposto |
File |
| Conteggio dei record |
Numero intero |
Nota: Record Count fornisce il numero totale di righe in Transposed CSV, non inclusa la riga di intestazione.
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Non è riuscita la trasposizione del file di input |
Unpivot
Per consolidare più colonne di dati, come ad esempio i periodi di tempo nei dati finanziari, in un'unica colonna con più righe, usa il comando Unpivot. Ad esempio, dati questi dati:
ANNO,MISURA,PRODOTTO,MERCATO,SCENARIO,GEN,FEB,MAR,APR,MAGGIO,GIUGNO,LUGLIO,AGOSTO,SET,OTTO,NOV,DIC FY20,Vendite,100-10,New York,effettivo,100,200,300,400,500,600,700,800,900,1000,1100,1200 FY20,Sales,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225
Puoi scorporare gli importi mensili nelle nuove colonne Periodo e Importo:
ANNO,MISURA,PRODOTTO,MERCATO,SCENARIO,Periodo,Importo FY20,Vendite,100-10,Massachusetts,effettivo,GEN,125 FY20,Vendite,100-10,Massachusetts,effettivo,FEB,225 FY20,Vendite,100-10,Massachusetts,effettivo,MAR,325 FY20,Vendite,100-10,Massachusetts,effettivo,APR,425 FY20,Vendite,100-10,Massachusetts,effettivo,MAGGIO,525 FY20,Vendite,100-10,Massachusetts,effettivo,GIUGNO,625 FY20,Vendite,100-10,Massachusetts,effettivo,LUGLIO,725 FY20,Vendite,100-10,Massachusetts,effettivo,AGOSTO,825 FY20,Vendite,100-10,Massachusetts,effettivo,SETTEMBRE,925 FY20,Vendite,100-10,Massachusetts,effettivo,OTTO,1025 FY20,Vendite,100-10,Massachusetts,effettivo,NOV,1125 FY20,Vendite,100-10,Massachusetts,Effettivo,DIC,1225 FY20,Vendite,100-10,New York,Effettivo,GEN,100 FY20,Vendite,100-10,New York,Effettivo,FEB,200 FY20,Vendite,100-10,New York,Effettivo,MAR,300 FY20,Vendite,100-10,New York,Effettivo,APR,400 FY20,Vendite,100-10,New York,Effettivo,MAGGIO,500 FY20,Vendite,100-10,New York,effettivo,GIUGNO,600 FY20,Vendite,100-10,New York,effettivo,LUGLIO,700 FY20,Vendite,100-10,New York,effettivo,AGOSTO,800 FY20,Vendite,100-10,New York,effettivo,SET,900 FY20,Vendite,100-10,New York,effettivo,OTTO,1000 FY20,Vendite,100-10,New York,effettivo,NOV,1100 FY20,Vendite,100-10,New York,effettivo,DIC,1200
Proprietà
| Proprietà |
Dettaglio |
| File di input |
Inserisci il file con i dati da decomprimere. |
| Delimitatore |
Seleziona il delimitatore utilizzato per separare i campi in File di input. |
| Aggregazione |
Seleziona la modalità di aggregazione dei valori non quotati:
- SUM, per aggregare i record quando i loro valori sono uguali in tutte le colonne. Consigliato.
- NONE, per creare righe duplicate con il valore univoco di ogni record.
|
| Nuova etichetta di colonna |
Inserisci l'intestazione della colonna nell'output con le righe basate sulle colonne non quotate. Nell'esempio precedente, Periodo. |
| Intestazione della colonna dati |
Inserisci l'intestazione della colonna nell'output con i dati delle colonne non quotate. Nell'esempio precedente, Importo. |
| Intestazioni dei dati |
Per disimpegnare specifiche colonne, elenca le loro intestazioni, premendo Invio tra una e l'altra. Nell'esempio precedente, GEN, FEB, MAR, e così via. |
| Nome della colonna pivot iniziale |
Per unificare un intervallo di colonne con l'intestazione , inserisci il nome della prima colonna dell'intervallo. Nell'esempio precedente, JAN. |
| Nome della colonna pivot finale |
Per unificare un intervallo di colonne con l'intestazione , inserisci il nome dell'ultima colonna dell'intervallo. Nell'esempio precedente, DEC. Nota: Se inserisci Nome della colonna pivot iniziale ma no Nome della colonna pivot finale, il comando la disattiva e tutte le colonne a destra di Nome della colonna pivot iniziale. Può essere utile con i dati prodotti dalle previsioni variabili. |
| Indice iniziale della colonna pivot |
Per disgiungere un intervallo di colonne dalla posizione , inserisci il valore dell'indice della prima colonna dell'intervallo. Utilizza un indice a base zero, dove le colonne del file di input iniziano con 0. Nell'esempio precedente, 5. |
| Indice finale della colonna pivot |
Per disgiungere un intervallo di colonne dalla posizione , inserisci il valore dell'indice dell'ultima colonna dell'intervallo. Utilizza un indice a base zero, in cui le colonne del file di input iniziano con 0. Nell'esempio precedente, 16. Nota: Se inserisci Indice della colonna pivot iniziale ma no Indice della colonna pivot finale, il comando lo disattiva e tutte le colonne a destra di Indice della colonna pivot iniziale. Questo può essere utile con i dati prodotti dalle previsioni variabili. |
| Anteprima dei risultati |
Per attivare un'anteprima dell'output non quotato, seleziona questa casella. |
Output
| Output |
Tipo di output |
| Risultato non quotato |
File |
Codici di uscita
| Codice |
Tipo |
Dettaglio |
| 0 |
Operazione completata |
Operazione completata |
| 1 |
Errore |
Argomenti non validi |
| 2 |
Errore |
Errore generale |
| 14 |
Errore |
Posizione del file di output non valida |
| 15 |
Errore |
Il carattere di escape utilizzato in File di input, di solito un ". |
Risoluzione dei problemi
Se un comando non va a buon fine, verifica la presenza di questi problemi comuni.
Delimitatore sbagliato
Se viene impostato un delimitatore sbagliato quando configuri un comando di trasformazione, la trasformazione non verrà eseguita come previsto.
Non è un CSV corretto
Se il dataset tabellare non è un CSV corretto, il comando di trasformazione non verrà eseguito, in quanto controlla che il formato sia conforme a RFC 4180 prima di elaborare l'input. Un CSV corretto:
- Memorizza i dati in testo normale utilizzando un set di caratteri come ASCII, Unicode (ad esempio, UTF-8), EBCDIC o Shift JIS.
- Consiste in record con un record per riga e record divisi in campi separati da delimitatori, in genere un singolo carattere riservato come una virgola, un punto e virgola o una tabulazione. A volte il delimitatore può includere spazi opzionali.
- Ha la stessa sequenza di campi per ogni record di
- In genere si tratta di un file piatto o di un report di dati relazionali
Numero incoerente di colonne per ogni record
Se i record di un dataset tabellare hanno un numero di colonne diverso, il comando di trasformazione rileva che non si tratta di un CSV corretto.
Conteggio delle colonne diverso
La combinazione di due tabulati CSV con un numero di colonne diverso non funzionerà e il comando Stack Files visualizzerà un errore.