Pour préparer les données DSV (Delimiter-Separated Values) au téléchargement, par exemple pour masser les données tabulaires dans le format requis, ajoutez une étape dans une chaîne qui utilise une commande de connexion Tabular Transformation. Par exemple :
- Diviser les ensembles de données en fonction du contenu d'un enregistrement
- Filtre basé sur des règles
- Combiner des ensembles de données provenant de sources multiples
Pour activer ces commandes, un administrateur informatique crée d'abord un connecteur de transformation tabulaire.
Ajouter un en-tête
Pour ajouter une ligne d'en-tête à un fichier de valeurs séparées par des virgules (CSV), utilisez la commande Add Header.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Saisissez le fichier auquel ajouter les en-têtes. |
| Séparateur |
Sélectionnez le délimiteur utilisé pour séparer les colonnes dans Fichier d'entrée. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
| Ligne d'en-tête |
Saisir tout le contenu de la ligne d'en-tête. Séparez chaque en-tête par un délimiteur, par exemple Column1,Column2,Column3. |
| Délimiteur d'en-tête |
Saisissez le délimiteur utilisé pour séparer les en-têtes dans la ligne d'en-tête , par exemple , |
Sorties
| Sortie |
Type de sortie |
| CSV avec en-têtes |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
Ajouter des numéros de ligne
Pour ajouter un numéro de ligne à la DSV dans la première colonne, utilisez la commande Add Row Numbers.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Saisir le fichier auquel ajouter des numéros de ligne. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Saisissez le délimiteur utilisé pour séparer les colonnes dans le fichier d'entrée . |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Ajouter des numéros de ligne à la sortie |
Fichier |
| Nombre d'enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Requête avancée
Pour exécuter une requête SQL sur un ou plusieurs fichiers CSV, utilisez la commande Advanced Query. Vous pouvez également joindre d'autres fichiers à cette commande.
Remarque : Cette commande prend en charge les instructions SELECT et les instructions complémentaires JOIN, mais pas les instructions telles que INSERT, UPDATE, ou CREATE. Pour insérer des lignes, utilisez la commande Stack Files; pour mettre à jour des lignes, Find and Replace.
Propriétés
| Propriété |
Détail |
| Tableaux |
Saisissez tous les fichiers à utiliser dans la requête, ainsi que leur nom de table. |
| Requête |
Saisissez la requête SQL à exécuter, comme syntaxe SQLite:
- Si les noms de colonnes ou les identifiants contiennent des espaces ou des caractères spéciaux, utilisez des crochets. Par exemple,
[Colonne A], [Colonne B].
- Pour formater des données avec deux espaces décimaux, utilisez la syntaxe suivante :
SELECT PRINTF('%.2f',(SUM(DATA))) AS EBITDA FROM HFMDat.
- Pour sélectionner la première instance d'un doublon, par exemple si deux enregistrements ont le même
ID, utilisez la syntaxe select * from group by ID having MIN(ID) ORDER BY ID.
- Pour concaténer plusieurs chaînes de caractères, utilisez l'opérateur
|| tel que string1 || string2 [ || string_n ].
|
| Délimiteur d'entrée |
Sélectionnez le délimiteur utilisé dans Tables, ainsi que dans les fichiers de jointure. |
| Délimiteur de sortie |
Sélectionnez le délimiteur à utiliser dans les résultats de la requête. |
| Aperçu |
Pour imprimer un aperçu des résultats de la requête, cochez cette case. |
La commande Advanced Query tente automatiquement de déterminer le type de données d'une colonne. Pour conserver les zéros en tête d'une valeur que la commande confond avec un nombre entier, utilisez les commandes Rechercher et remplacer - avec Regex et Remplacer les correspondances uniquement sélectionnées - pour ajouter des guillemets simples (') autour des valeurs de la colonne et les supprimer à la fin de la commande Advanced Query:
- Pour ajouter des guillemets simples, recherchez
(\d ), et remplacez par '$1'.
- Pour supprimer les guillemets simples, recherchez
'(\d )', et remplacez par $1.
Lorsque Regex est sélectionné, la commande Rechercher et remplacer utilise les parenthèses (()) pour capturer le groupe ou les caractères, puis les remplace en tant que premier paramètre $1. Pour créer des captures multiples, utilisez des jeux de parenthèses successifs et des valeurs incrémentielles telles que $2.
Sorties
| Sortie |
Type de sortie |
| Résultat |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Modifier le délimiteur
Pour modifier le délimiteur d'un fichier CSV, utilisez la commande Change Delimiter.
Note : Pour se conformer à la spécification RFC, utilise toujours un seul caractère comme délimiteur, de préférence une virgule ou une tabulation.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Délimiteur d'entrée |
Saisissez le délimiteur actuellement utilisé dans le fichier d'entrée . Pour un caractère de tabulation, entrez \t. |
| Délimiteur de sortie |
Saisir le délimiteur à utiliser après la transformation. Pour un caractère de tabulation, entrez \t. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
| Conserver les lignes vides |
Cochez cette case pour conserver des lignes vides dans vos résultats. Ils sont supprimés par défaut. |
Sorties
| Sortie |
Type de sortie |
| Résultat CSV |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
Nettoyer les nouvelles lignes sans guillemets
Pour tenter de nettoyer un fichier conforme à la norme RFC (Request for Comments), à l'exception des caractères de nouvelle ligne non citée, utilisez la commande Clean Unquoted Newlines (Nettoyer les nouvelles lignes non citées). Par exemple, cette commande permet de traiter des fichiers de données contenant des caractères incohérents pour les retours chariot ou les nouvelles lignes.
Note : Cette commande ne nettoie que les nouvelles lignes sans guillemets. D'autres problèmes de non-conformité entraîneront toujours l'échec de l'ensemble de données.
Propriétés
| Propriété |
Détail |
| Prévisualisation du résultat |
Pour prévisualiser le résultat dans le journal de la commande, cochez cette case. |
| Fichier d'entrée |
Saisissez le fichier à nettoyer. |
| Délimiteur de fichier |
Sélectionnez le délimiteur pour chaque colonne dans Fichier d'entrée. |
| Utiliser des guillemets paresseux |
Pour permettre aux guillemets d'apparaître dans les champs sans guillemets et aux guillemets non doubles d'apparaître dans les champs avec guillemets, cochez cette case. |
| Ajouter du texte à la fin |
Pour ajouter à la dernière valeur de la dernière colonne de l'enregistrement précédent toute ligne d'une seule colonne sans délimiteur dans le fichier d'entrée , cochez cette case.
|
Sorties
| Sortie |
Type de sortie |
| Sortie des nouvelles lignes nettoyée |
Fichier |
| Nombre de lignes |
Entier |
Note : La sortie Line count fournit le nombre total d'enregistrements - y compris l'en-tête - dans la sortie Cleaned newlines output.
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Échec de la création de la sortie de la nouvelle ligne nettoyée |
Filtre à colonne
Pour filtrer les colonnes DSV dont les en-têtes correspondent au modèle spécifié, utilisez la commande Column Filter.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Type de motif |
Sélectionnez le type de motif à filtrer :
-
Index pour filtrer par index de colonne
-
Exact pour filtrer par une liste de valeurs exactes séparées par des virgules.
-
Regex pour filtrer par une expression régulière
|
| Modèle |
Saisir le modèle de correspondance entre les colonnes. Si Le type de motif est Index, appliquez l'opérateur d'étalement, tel que 1:5,7:8,10:15. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
| Inverse |
Pour conserver les colonnes correspondantes et supprimer toutes les autres, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Sortie du filtre de la colonne |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Concat des fichiers
Pour fusionner horizontalement plusieurs fichiers de sources de données tabulaires en un seul ensemble de données CSV, utilisez la commande Concat Files.
Propriétés
| Propriété |
Détail |
| Fichiers sources |
Entrez les fichiers à concaténer. |
| Prévisualisation du résultat |
Pour prévisualiser le résultat dans le journal de la commande, cochez cette case. |
| Délimiteur de fichier |
Sélectionnez le délimiteur utilisé dans les fichiers source . |
Sorties
| Sortie |
Type de sortie |
| CSV fusionné |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Échec de la génération d'un CSV |
Convertir CSV en XLSX
Pour convertir un fichier CSV en classeur Microsoft Excel® (XLSX), utilisez la commande Convert CSV to XLSX.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à convertir en XLSX. |
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Nom de la feuille |
Saisissez le nom de la feuille à créer dans le classeur Excel. |
| Fichier de sortie |
Indiquez le chemin d'accès où stocker le fichier (facultatif). En cas d'utilisation comme sortie pour une autre commande de la chaîne, laisser vide. |
Sorties
| Sortie |
Type de sortie |
| Sortie XLSX |
Fichier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
Convertir JSON en CSV
Pour convertir un fichier JSON en fichier CSV, utilisez la commande Convert JSON to CSV.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier JSON à convertir en CSV. |
| Fichier de sortie |
Saisissez le chemin d'accès à l'endroit où vous souhaitez enregistrer le nouveau fichier CSV. En cas d'utilisation comme sortie pour une autre commande de la chaîne, laisser vide. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Sortie CSV |
Fichier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
Convertir en tableau croisé
Pour convertir un ensemble de données tabulaires - tel qu'un résultat de requête Oracle Essbase® multidimensional expressions (MDX) - en un format de tableau croisé, ou crosstab, utilisez la commande Convert to Cross-Tab. Cette commande base la présentation du tableau croisé sur les en-têtes de colonnes et de lignes définis comme des tuples dans l'ensemble de données tabulaires d'entrée.
Par exemple, avec cette commande, cet ensemble de données :
(Mesures, Produit, Marché) (Réel, Trim. 1) (Réel, Trim. 2) (Réel, Trim. 3) (Réel, Trim. 4) (Budget, Trim. 1) (Budget, Trim. 2) (Budget, Trim. 3) (Budget, Trim. 4) (Ventes, 100-10, New York) 1995.0 2358.0 2612.0 1972.0 2249.0 2220.0 2470.0 1720.0 (Ventes, 100-10, Massachusetts) 1456.0 1719.0 1905.0 1438.0 1360.0 1620.0 1800.0 1250.0 (Ventes, 100-10, Floride) 620.0 735.0 821.0 623.0 570.0 690.0 770.0 530.0 (Ventes, 100-10, Connecticut) 944.0 799.0 708.0 927.0 880.0 750.0 660.0 810.0 (Ventes, 100-10, New Hampshire) 353.0 413.0 459.0 345.0 320.0 370.0 430.0 280.0 (Ventes, 100-10, Californie) 1998.0 2358.0 2612.0 1972.0 2480.0 2940.0 3250.0 2530.0 (Ventes, 100-10, Oregon) 464.0 347.0 345.0 370.0 570.0 420.0 420.0 470.0
peut devenir un tableau croisé délimité par des tabulations :
Réel Réel Réel Réel Budget Budget Budget Trim. 1 Trim. 2 Trim. 3 Trim. 4 Trim. 1 Trim. 2 Trim. 3 Trim. 4 Chiffre d'affaires 100-10 New York 1995.0 2358.0 2612.0 1972.0 2249.0 2220.0 2470.0 1720.0 Ventes 100-10 Massachusetts 1456.0 1719.0 1905.0 1438.0 1360.0 1620.0 1800.0 1250.0 Ventes 100-10 Floride 620.0 735.0 821.0 623.0 570.0 690.0 770.0 530.0 Ventes 100-10 Connecticut 944.0 799.0 708.0 927.0 880.0 750.0 660.0 810.0 Ventes 100-10 New Hampshire 353.0 413.0 459.0 345.0 320.0 370.0 430.0 280.0 Ventes 100-10 Californie 1998.0 2358.0 2612.0 1972.0 2480.0 2940.0 3250.0 2530.0 Ventes 100-10 Oregon 464.0 347.0 345.0 370.0 570.0 420.0 420.0 470.0
Sample configuration
La configuration se présente comme suit :
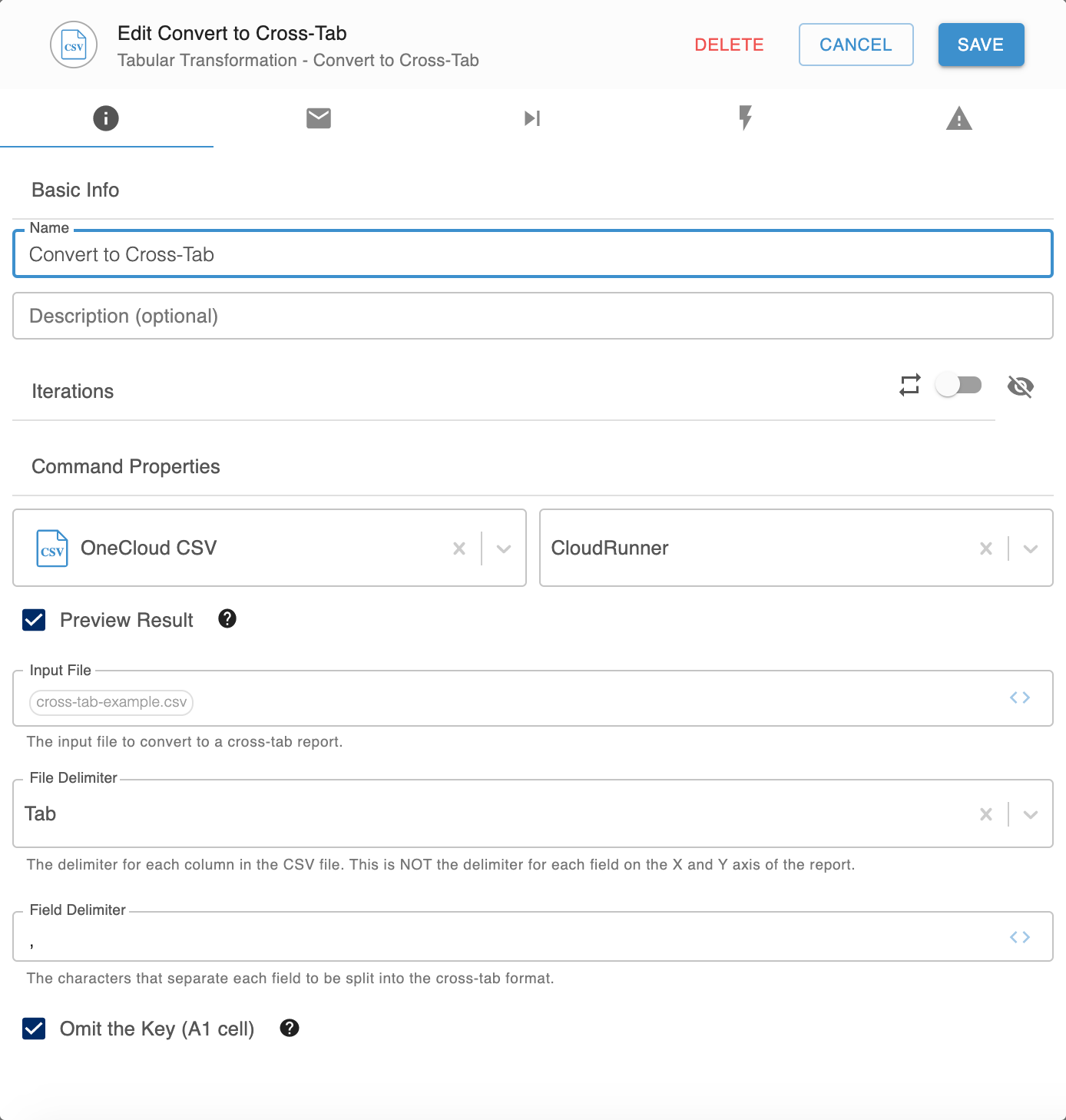
Propriétés
| Propriété |
Détail |
| Prévisualisation du résultat |
Pour prévisualiser le format du tableau croisé, cochez cette case. |
| Fichier d'entrée |
Saisissez le fichier à convertir au format tableau croisé, les en-têtes de colonnes et de lignes étant définis comme des tuples. Note : Configurer le fichier d'entrée de sorte que sa première colonne soit un ensemble délimité de valeurs à répartir horizontalement et que sa première ligne soit un ensemble délimité de valeurs à répartir verticalement. |
| Délimiteur de fichier |
Sélectionnez le délimiteur utilisé avec les colonnes dans Fichier d'entrée. |
| Délimiteur de champ |
Saisissez le caractère à utiliser pour séparer chaque champ dans le format du tableau croisé. |
| Omettre la clé (cellule A1) |
Pour ne pas tenir compte de la cellule A1 du fichier d'entrée dans le format du tableau croisé, cochez cette case. Par exemple, si la cellule A1 contient (A,B), les cellules A1 et A2 du format tableau croisé sont vides |
Sorties
| Sortie |
Type de sortie |
| Rapport croisé |
Fichier |
| Nombre de lignes |
Entier |
Note : La sortie Line count fournit le nombre total de lignes dans la sortie Crosstab report, y compris toutes les lignes d'en-tête.
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
Convertir XLSX en CSV
La version de cette commande relative à la transformation tabulaire n'est plus utilisée. Toute chaîne existante utilisant cette commande continuera à fonctionner, mais aucune instance future ne pourra être créée.
Nous recommandons plutôt d'utiliser la commande Worksheet to CSV du connecteur Excel.
Copier la colonne
Pour copier une colonne à partir d'un fichier DSV, utilisez la commande Copy Column.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Nom de la colonne |
Saisissez le nom de la colonne à copier. |
| Nouveau nom de colonne |
Saisir le nom de la copie résultante de la colonne. |
| Insérer un index |
Saisir l'indice de la colonne à laquelle insérer la copie de la colonne. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Copier la sortie de la colonne |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée, généralement un " |
Valeur de l'extrait
Pour extraire une valeur d'un fichier DSV en fonction de l'indice de ligne et de l'indice de colonne, utilisez la commande Extract Value.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Indice de ligne |
Saisissez le numéro de la ligne à partir de laquelle la valeur doit être extraite, la première ligne du fichier d'entrée étant 1. |
| Index des colonnes |
Saisir le numéro de colonne de l'entrée Row index à extraire. Pour extraire la totalité de la ligne, ne rien indiquer. |
Sorties
| Sortie |
Type de sortie |
| Ligne |
JSON |
| Valeur |
Chaîne |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
Filtrer les rangs
Pour filtrer les lignes du DSV à l'aide d'une expression régulière (regex) ou d'une correspondance exacte avec une ou plusieurs colonnes de la ligne, utilisez la commande Filter Rows.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Trouver un modèle |
Saisissez le modèle à utiliser pour rechercher les correspondances. |
| Type de modèle de correspondance |
Indiquez si la correspondance doit se faire avec un motif Regex ou Exact. |
| Insensible à la casse |
Pour ignorer la casse du texte, cochez cette case. |
| Inverse |
Pour conserver toutes les lignes correspondantes et rejeter les autres, cochez cette case. |
| Colonnes de recherche |
Saisissez une liste d'index de colonnes séparés par des virgules pour limiter la recherche. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case |
Note : La commande Filter Rows attend un fichier DSV correct avec des en-têtes. Pour filtrer la première ligne d'un fichier sans en-têtes, utilisez la commande Find de une connexion File Utilities.
Sorties
| Sortie |
Type de sortie |
| Sortie de la ligne de filtre |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Find and replace (Rechercher et remplacer)
Pour rechercher et remplacer des valeurs de colonne dans les données sur la base d'une expression régulière , d'une chaîne de texte complète ou d'un index de colonne, utilisez la commande Find and Replace.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Indiquer s'il faut produire le fichier original ou une copie :
- Pour obtenir le fichier original avec ses valeurs de colonnes mises à jour, entrez le même fichier que Fichier d'entrée.
- Pour éditer une copie de l'original avec les valeurs de colonne mises à jour, saisissez le nom du nouveau fichier.
|
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Trouver un modèle |
Saisissez l'expression régulière, la chaîne de texte ou l'index de colonne à utiliser pour identifier les valeurs à remplacer, sur la base de Type de modèle de correspondance. |
| Type de modèle de correspondance |
Sélectionnez la manière d'identifier les valeurs de colonne à rechercher :
- Pour trouver des valeurs basées sur une expression régulière, sélectionnez
Regex.
- Pour trouver des valeurs qui correspondent à une chaîne de texte complète, sélectionnez
Exact.
- Pour trouver des valeurs en fonction de leur colonne, sélectionnez
Index.
Note : Exact correspond à la chaîne complète dans chaque colonne. Pour rechercher et remplacer une valeur partielle par une colonne, sélectionnez Regex et Remplacer uniquement les correspondances. |
| Valeur de remplacement |
Saisissez le texte par lequel vous souhaitez remplacer les valeurs correspondantes. Remarque : Si Le type de modèle de correspondance est Index, la valeur de remplacement remplace toutes les valeurs de la colonne correspondante. |
| Insensible à la casse |
Pour ignorer la casse du texte, cochez cette case. |
| Remplacer uniquement les correspondances |
Si Le type de modèle de correspondance est Regex, cochez cette case pour remplacer uniquement le texte correspondant par la valeur de remplacement. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
| Colonnes |
Entrez une liste de colonnes séparées par des virgules, avec 0 pour la première colonne. Par exemple, 0,1,2,3 limite la commande aux quatre premières colonnes. |
Remarque : Pour appliquer la même entrée Replacement Value à plusieurs valeurs, utilisez une expression régulière comme entrée Find Pattern, telle que (?:Variance|Variance %|Toutes les périodes|FY15|YTD).
Sorties
| Sortie |
Type de sortie |
| Résultats de la recherche et du remplacement |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Insérer une colonne
Pour insérer une colonne dans un fichier DSV, utilisez la commande Insert Column.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Texte de l'en-tête |
Saisissez le nom du nouvel en-tête de colonne. |
| Valeur des données |
Saisissez le texte à insérer dans la nouvelle colonne. |
| Insérer un index |
Saisir l'indice de la colonne à laquelle insérer la nouvelle colonne. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
Note : Pour insérer plusieurs colonnes, ajoutez une colonne au fichier d'entrée avec un en-tête EMPTY_REPLACED_HEADER, avec une valeur pour chaque ligne de EMPTY_REPLACED_VALUE. Avec la connexion File Utilities, utilisez les commandes Find and Replace pour remplacer l'en-tête par l'en-tête de colonne souhaité et la valeur par une chaîne contenant le nombre de virgules nécessaires.
Sorties
| Sortie |
Type de sortie |
| Insérer une sortie de colonne |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Joindre des colonnes
Pour joindre plusieurs colonnes d'un fichier DSV et, éventuellement, éliminer les colonnes utilisées, utilisez la commande Join Columns.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur de Fichier d'entrée. |
| Index de la colonne jointe |
Saisissez l'indice numérique de la nouvelle colonne. Pour la première colonne, inscrivez 0. |
| Type de modèle de correspondance |
Sélectionnez le type de modèle à utiliser pour la recherche de colonnes :
- Pour effectuer une recherche par emplacement de colonne, sélectionnez Index.
- Pour saisir une liste d'en-têtes séparés par des virgules, sélectionnez Exact.
- Pour utiliser l'expression régulière , sélectionnez Regex.
|
| Modèle de correspondance |
Saisir le modèle ou l'index à utiliser pour trouver les colonnes à joindre. |
| En-tête de colonne jointe |
Saisissez le nom de la nouvelle colonne créée à partir de la jointure. |
| Rejoindre le texte |
Saisissez le texte qui relie les valeurs dans la nouvelle colonne, par exemple -. |
| Ignorer |
Pour supprimer les colonnes jointes afin de créer la nouvelle, cochez cette case. |
| Résultats en avant-première |
Pour prévisualiser les 10 premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Sortie de la colonne de jointure |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
En-têtes de carte
Pour remplacer une liste d'en-têtes par une autre liste d'en-têtes, utilisez la commande Map Headers. Dans les listes, séparez les en-têtes par des virgules et respectez l'ordre.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur de Fichier d'entrée. |
| En-têtes d'entrée |
Saisir une liste d'en-têtes à remplacer par de nouvelles valeurs, dans le même ordre que En-têtes de sortie. |
| En-têtes de sortie |
Saisir une liste des nouveaux en-têtes à inclure dans la sortie, dans le même ordre que En-têtes d'entrée. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
| Utiliser des index |
Si En-têtes d'entrée utilise des index numériques, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Sortie des en-têtes de carte |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Pivot
Pour représenter les valeurs d'une colonne de données sous forme de colonnes distinctes, utilisez la commande Pivot. Lorsque vous faites pivoter une colonne, les valeurs uniques de ses lignes deviennent de nouveaux en-têtes de colonne.
Par exemple, si l'on considère ces données :
ANNÉE,MESURE,PRODUIT,MARCHÉ,SCÉNARIO,Période,Montant FY20,Sales,100-10,Massachusetts,Actual,JAN,125 FY20,Sales,100-10,Massachusetts,Actual,FEB,225 AF20,Ventes,100-10,Massachusetts,Réel,MAR,325 AF20,Ventes,100-10,Massachusetts,Réel,APR,425 AF20,Ventes,100-10,Massachusetts,Réel,MAI,525 AF20,Ventes,100-10,Massachusetts,Actual,JUN,625 FY20,Sales,100-10,Massachusetts,Actual,JUL,725 FY20,Sales,100-10,Massachusetts,Actual,AUG,825 FY20,Sales,100-10,Massachusetts,Actual,SEP,925 FY20,Sales,100-10,Massachusetts,Actual,OCT,1025 FY20,Sales,100-10,Massachusetts,Actual,NOV,1125 FY20,Sales,100-10,Massachusetts,Effectif,DEC,1225 EXERCICE20,COGS,100-10,Massachusetts,Effectif,JAN,100 EXERCICE20,COGS,100-10,Massachusetts,Effectif,FEB,200 EXERCICE20,COGS,100-10,Massachusetts,Effectif,MAR,300 EXERCICE20,COGS,100-10,Massachusetts,Effectif,APR,400 EXERCICE20,COGS,100-10,Massachusetts,Effectif,MAI,500 EXERCICE20,COGS,100-10,Massachusetts,Actual,JUN,600 FY20,COGS,100-10,Massachusetts,Actual,JUL,700 FY20,COGS,100-10,Massachusetts,Actual,AUG,800 FY20,COGS,100-10,Massachusetts,Actual,SEP,900 EXERCICE 20, COGS,100-10,Massachusetts,Réel,OCT,1000 EXERCICE 20, COGS,100-10,Massachusetts,Réel,NOV,1100 EXERCICE 20, COGS,100-10,Massachusetts,Réel,DEC,1200
Si vous faites pivoter la colonne MEASURE, que vous agrègez la colonne Amount et que vous spécifiez les colonnes restantes en tant que lignes, la sortie remplace la colonne MEASURE par des colonnes pour ses valeurs Sales et COGS et fournit leurs montants respectifs :
ANNÉE,PRODUIT,MARCHÉ,SCÉNARIO,Période,Ventes,COGS FY20,100-10,Massachusetts,Actual,APR,425,400 FY20,100-10,Massachusetts,Actual,AUG,825,800 FY20,100-10,Massachusetts,Actual,DEC,1225,1200 FY20,100-10,Massachusetts,Actual,FEB,225,200 FY20,100-10,Massachusetts,Actual,JAN,125,100 FY20,100-10,Massachusetts,Actual,JUL,725,700 FY20,100-10,Massachusetts,Actual,JUN,625,600 FY20,100-10,Massachusetts,Actual,MAR,325,300 FY20,100-10,Massachusetts,Actual,MAY,525,500 FY20,100-10,Massachusetts,Actual,NOV,1125,1100 FY20,100-10,Massachusetts,Actual,OCT,1025,1000 FY20,100-10,Massachusetts,Actual,SEP,925,900
Si vous excluez la colonne Period des lignes, toutes les périodes sont agrégées pour chaque combinaison des lignes restantes :
ANNÉE,PRODUIT,MARCHÉ,SCÉNARIO,Ventes,COGS EF20,100-10,Massachusetts,Réel,8100,7800
Si vous faites pivoter les colonnes MEASURE et Period, chaque combinaison unique de leurs valeurs apparaît sous forme de colonnes, telles que Sales-JAN, Sales-FEB, COGS-JAN, et ainsi de suite :
YEAR,PRODUCT,MARKET,SCENARIO,Sales-JAN,Sales-FEB,Sales-MAR,Sales-APR,Sales-MAY,Sales-JUN,Sales-JUL,Sales-AUG,Sales-SEP,Sales-OCT,Sales-NOV,Sales-DEC,COGS-JAN,COGS-FEB,COGS-MAR,COGS-APR,COGS-MAY,COGS-JUN,COGS-JUL,COGS-AUG,COGS-SEP,COGS-OCT,COGS-NOV,COGS-DEC FY20,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225,100,200,300,400,500,600,700,800,900,1000,1100,1200
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Saisissez le fichier contenant les données à croiser. |
| Séparateur |
Sélectionnez le délimiteur utilisé pour séparer les champs dans le fichier d'entrée . |
| Agrégation |
Sélectionnez la méthode d'agrégation des valeurs pivotées :
- SUM, pour regrouper les enregistrements ayant les mêmes valeurs de ligne en un seul enregistrement. Recommandé.
- NONE, pour créer plusieurs lignes pour un seul ensemble de valeurs équivalentes. Chaque ligne de la colonne pivotée sera remplie, mais d'autres peuvent inclure NULL.
|
| Valeurs à agréger |
Saisissez la colonne contenant les données à inclure dans les lignes des colonnes pivotantes, comme la colonne Amount dans l'exemple précédent. |
| Colonnes pivotantes |
Saisissez les colonnes avec les valeurs de ligne à utiliser comme en-têtes de colonne. S'il s'agit de plusieurs colonnes, une colonne distincte apparaît pour chaque combinaison unique de leurs valeurs. |
| Délimiteur de colonne |
Si plusieurs colonnes Pivot, saisissez le délimiteur à utiliser pour séparer leurs valeurs dans les nouveaux en-têtes de colonne. |
| Lignes pivot |
Saisir les colonnes du fichier d'entrée à conserver. Dans le résultat, chaque combinaison unique des valeurs de ces colonnes apparaît sous forme de lignes. Ne pas entrer les mêmes colonnes que Valeurs à agréger ou Colonnes pivots. |
| Résultats en avant-première |
Pour activer l'aperçu des données pivotées, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Résultat pivoté |
Fichier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans Fichier d'entrée, généralement un ". |
Réorganiser les colonnes
Pour réorganiser les colonnes d'un fichier DSV, utilisez la commande Reorder columns. Vous pouvez identifier les colonnes par leur nom ou leur index.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Commandes de colonnes |
Saisir un tableau de colonnes ou d'intervalles individuels provenant du fichier d'entrée , dans l'ordre dans lequel ils doivent apparaître dans le fichier transformé. Pour spécifier des colonnes, utilisez leur nom ou leur index, en commençant par 1. Par exemple, entrez 4:6 ou ColA:ColC pour spécifier une plage, ou 7 ou ColH pour une colonne individuelle. Note : Toutes les colonnes du fichier d'entrée qui ne sont pas incluses dans L'ordre des colonnes apparaît à la fin des colonnes du fichier transformé, dans le même ordre que dans le fichier d'entrée . |
| Résultats en avant-première |
Pour afficher un aperçu des résultats - l'en-tête et les 10 premières lignes - dans la sortie de la commande, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Fichier transformé |
Fichier |
| Rangs transformés |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
Filtres intelligents
Pour appliquer les critères de plusieurs groupes de filtres - basés sur des valeurs de texte, de date ou de nombre - aux lignes d'un fichier DSV, utilisez la commande Smart Filter Rows. Vous pouvez filtrer les lignes par expression régulière ou une correspondance exacte d'une ou plusieurs de leurs colonnes.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur utilisé dans Fichier d'entrée. |
| Inverse |
Pour conserver - et non supprimer - toutes les lignes qui correspondent à Filtres, cochez cette case. |
| Filtres |
Pour configurer les filtres de texte, de nombre ou de date à appliquer au fichier d'entrée , sélectionnez l'opérateur pour les groupes de filtres - ET ou OU - et configurez les critères pour chacun d'entre eux. Pour un groupe de filtres texte:
- Dans Column Name, saisissez le nom de la colonne à filtrer.
- Pour ignorer la casse de Nom de la colonne et Texte de comparaison, sélectionnez Insensible à la casse.
- Dans Condition et Comparez le texte, saisissez les critères de la valeur à rechercher dans la colonne, tels que "Egal à [texte]" ou "Contient [texte]". <!--To apply
the inverse of the Condition
input, such as to match text that does not
equal or contain the Compare Text
input, select Not.-->
<!---
To remove any leading or trailing spaces from
matched text, select Trim.
-->
Pour un groupe de filtres number:
- Dans Format, sélectionnez le format du nombre à faire correspondre - entier ou décimal. S'il peut s'agir de l'un ou l'autre, sélectionnez Décimal.
- Dans Column Name, saisissez le nom de la colonne à filtrer.
- Dans Condition et Test Number, saisissez les critères de la valeur à rechercher dans la colonne, par exemple "égal à [nombre]" ou "inférieur à [nombre]". <!--To apply the inverse
of the Condition input,
such as to match numbers that do not
equal the Test Number input,
select Not.-->
<!---
To match numbers regardless of whether they're
positive or negative, select Absolute Value.
-->
Pour un groupe de filtres date:
- Dans Format, entrez le 2 janvier 2006 dans le format de la date à faire correspondre, par exemple 2006-01-02.
- Dans Column Name, saisissez le nom de la colonne à filtrer.
- Dans Condition et Comparez la date, saisissez les critères de la valeur à rechercher dans la colonne, par exemple "Egal à [date]" ou "Inférieur à [date]". <!--To
apply the inverse of the Condition
input, such as to match dates that do not
equal the Compare Date
input, select Not.-->
|
| Résultats en avant-première |
Pour afficher un aperçu des résultats dans la sortie de la commande, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Sortie de la rangée de filtres intelligents |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Fichier fractionné
Pour diviser un fichier en plusieurs fichiers sur la base d'un nombre d'enregistrements, utilisez la commande Split File. Par exemple, utilisez cette commande pour traiter de plus petits morceaux en parallèle afin d'améliorer les performances.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Saisissez le fichier à diviser en plusieurs fichiers. |
| Délimiteur de fichier |
Sélectionnez le délimiteur pour chaque colonne dans Fichier d'entrée. |
| Préparez l'en-tête |
Pour inclure l'en-tête du fichier d'entrée dans chaque morceau de fichier créé, cochez cette case.
|
| Enregistrements par fichier |
Saisissez le nombre maximal d'enregistrements à inclure dans chaque bloc de données. |
Sorties
| Sortie |
Type de sortie |
| Diviser les fichiers en morceaux |
Fichier |
| Nombre de morceaux |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Échec de la création des morceaux de fichiers |
Valeur de fractionnement
Pour diviser une colonne en plusieurs colonnes en fonction d'un délimiteur de valeur, utilisez la commande Split Value.
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Entrez le fichier à transformer. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur utilisé pour séparer les colonnes dans Fichier d'entrée. |
| Nouveaux en-têtes |
Saisissez une liste des nouveaux en-têtes à créer à partir de la valeur de fractionnement, dans l'ordre. |
| Nom de la colonne |
Saisissez l'en-tête de la colonne à diviser. |
| Délimiteur de valeur |
Saisissez le délimiteur sur lequel la valeur doit être divisée. |
| Colonne de rejet |
Pour supprimer la colonne en cours de fractionnement, cochez cette case. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Édition de valeurs fractionnées |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans Fichier d'entrée, généralement un ". |
Fichiers de pile
Pour empiler les valeurs d'une liste de fichiers de valeurs séparées par des délimiteurs (DSV) dans un ordre spécifié, utilisez la commande Stack Files. La ligne d'en-tête du premier fichier sera utilisée dans le nouveau fichier.
Note : Pour empiler des fichiers avec cette commande, ils doivent tous avoir le même nombre de colonnes. Pour empiler des fichiers asymétriques, utilisez le connecteur File Utils et sa commande Stack Files.
Propriétés
| Propriété |
Détail |
| Fichiers |
Saisir les fichiers DSV à empiler. |
| Fichier de sortie |
Saisir le nom du fichier résultant de la transformation. |
| Séparateur |
Sélectionnez le délimiteur utilisé pour séparer les colonnes dans les fichiers . |
| Fichier d'entrée |
Entrez les fichiers à empiler, séparés par une virgule. Note: En cas d'utilisation d'une boucle, ce champ est obligatoire (car les fichiers ne sont pas téléchargés dans la section Fichiers). La commande déclenchera une erreur "fichier non trouvé" si elle est ajoutée à la section Fichiers. |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Sortie des fichiers de pile |
Fichier |
| Nombre d’enregistrements |
Entier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans Fichier d'entrée, généralement un ". |
Transposer
Pour faire pivoter tous les champs d'un fichier délimité le long de ses axes horizontaux et verticaux, de sorte que les lignes deviennent des colonnes et vice versa, utilisez la commande Transpose. Par exemple, avec cette commande, ce CSV :
id,1,2,3,4
name, "Johnson, Smith, and Jones Co.", "Sam Smith",Barney & Co.,Johnson's Auto
amount,345.33,933.40,0,2344
remark,Paye en temps et en heure,, "Superbe collaboration",
devient :
id,name,amount,remark
1, "Johnson, Smith, and Jones Co",345.33,Paye à temps
2, "Sam Smith",933.40,
3,Barney & Co, "Superbe collaboration"
4,Johnson's Auto,2344,
Propriétés
| Propriété |
Détail |
| Résultats en avant-première |
Pour prévisualiser les dix premières lignes et l'en-tête des résultats de la transformation, cochez cette case. |
| Fichier d'entrée |
Entrez le fichier délimité à transposer. |
| Délimiteur de fichier |
Sélectionnez le délimiteur de chaque colonne de Fichier d'entrée. |
| Taille des morceaux |
Indiquez la taille maximale (en Mo) de chaque fichier de travail à traiter. |
Sorties
| Sortie |
Type de sortie |
| CSV transposé |
Fichier |
| Nombre d’enregistrements |
Entier |
Remarque : Record Count indique le nombre total de lignes dans Transposed CSV, sans y compris la ligne d'en-tête.
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Échec de la transposition du fichier d'entrée |
Unpivot
Pour consolider plusieurs colonnes de données - telles que des périodes de temps dans des données financières - en une seule colonne avec plusieurs lignes, utilisez la commande Unpivot. Par exemple, si l'on considère ces données :
ANNÉE,MESURE,PRODUIT,MARCHÉ,SCÉNARIO,JAN,FEB,MAR,APR,MAY,JUN,JUL,AUG,SEP,OCT,NOV,DEC FY20,Sales,100-10,New York,Actual,100,200,300,400,500,600,700,800,900,1000,1100,1200 FY20,Sales,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225
Vous pouvez dépivoter les montants mensuels dans les nouvelles colonnes Période et Montant:
ANNÉE,MESURE,PRODUIT,MARCHÉ,SCÉNARIO,Période,Montant Année 20, Ventes,100-10,Massachusetts,Réel,JAN,125 Année 20, Ventes,100-10,Massachusetts,Réel,FÉV,225 Année 20, Ventes,100-10,Massachusetts,Réel,MAR,325 Année 20, Ventes,100-10,Massachusetts,Réel,AVR,425 Année 20, Ventes,100-10,Massachusetts,Réel,MAY,525 FY20,Sales,100-10,Massachusetts,Actual,JUN,625 FY20,Sales,100-10,Massachusetts,Actual,JUL,725 FY20,Sales,100-10,Massachusetts,Actual,AUG,825 FY20,Sales,100-10,Massachusetts,Actual,SEP,925 FY20,Sales,100-10,Massachusetts,Actual,OCT,1025 FY20,Sales,100-10,Massachusetts,Actual,NOV,1125 AF20,Ventes,100-10,Massachusetts,Réel,DEC,1225 AF20,Ventes,100-10,New York,Réel,JAN,100 AF20,Ventes,100-10,New York,Réel,FEB,200 AF20,Ventes,100-10,New York,Réel,MAR,300 AF20,Ventes,100-10,New York,Réel,APR,400 AF20,Ventes,100-10,New York,Réel,MAI,500 AF20,Ventes,100-10,New York,Actual,JUN,600 FY20,Sales,100-10,New York,Actual,JUL,700 FY20,Sales,100-10,New York,Actual,AUG,800 FY20,Sales,100-10,New York,Actual,SEP,900 FY20,Sales,100-10,New York,Actual,OCT,1000 FY20,Sales,100-10,New York,Actual,NOV,1100 FY20,Sales,100-10,New York,Actual,DEC,1200
Propriétés
| Propriété |
Détail |
| Fichier d'entrée |
Saisir le fichier contenant les données à dépivoter. |
| Séparateur |
Sélectionnez le délimiteur utilisé pour séparer les champs dans le fichier d'entrée . |
| Agrégation |
Sélectionnez la méthode d'agrégation des valeurs non divisées :
- SUM, pour agréger des enregistrements dont les valeurs sont identiques dans toutes les colonnes. Recommandé.
- NONE, pour créer des lignes en double avec la valeur unique de chaque enregistrement.
|
| Nouvelle étiquette de colonne |
Saisir l'en-tête de la colonne dans l'édition avec des lignes basées sur les colonnes non pivotées. Dans l'exemple précédent, Période. |
| En-tête de colonne de données |
Saisir l'en-tête de la colonne dans l'édition avec les données pour les colonnes non pivotées. Dans l'exemple précédent, Montant. |
| En-têtes de données |
Pour déporter des colonnes spécifiques, énumérez leurs en-têtes, en appuyant sur Enter entre chacune d'elles. Dans l'exemple précédent, JAN, FEB, MAR, et ainsi de suite. |
| Nom de la colonne pivot de départ |
Pour dépivoter une plage de colonnes par header, entrez le nom de la première colonne de la plage. Dans l'exemple précédent, JAN. |
| Nom de la colonne pivot de fin |
Pour dépivoter une plage de colonnes par en-tête, entrez le nom de la dernière colonne de la plage. Dans l'exemple précédent, DEC. Note : Si vous entrez Nom de la colonne pivot de départ mais pas Nom de la colonne pivot de fin, la commande la dépivote et toutes les colonnes à droite de Nom de la colonne pivot de départ. Cela peut s'avérer utile pour les données produites par les prévisions glissantes. |
| Début de l'index de la colonne pivot |
Pour dépivoter une plage de colonnes par position, entrez la valeur de l'index de la première colonne de la plage. Utilisez un index basé sur le zéro, où les colonnes du fichier d'entrée commencent par 0. Dans l'exemple précédent, 5. |
| Indice de fin de colonne pivot |
Pour dépivoter une plage de colonnes par position, entrez la valeur de l'index de la dernière colonne de la plage. Utilisez un index à base zéro, dans lequel les colonnes du fichier d'entrée commencent par 0. Dans l'exemple précédent, 16. Note : Si vous entrez l'indice de la colonne pivot de départ mais pas l'indice de la colonne pivot de fin, la commande la dépivote et toutes les colonnes à droite de l'indice de la colonne pivot de départ. Cela peut s'avérer utile pour les données produites par les prévisions glissantes. |
| Résultats en avant-première |
Pour activer l'aperçu de la sortie non divisée, cochez cette case. |
Sorties
| Sortie |
Type de sortie |
| Résultat sans pivot |
Fichier |
Codes de sortie
| Code |
Type |
Détail |
| 0 |
Réussite |
Réussite |
| 1 |
Erreur |
Arguments non valables |
| 2 |
Erreur |
Échec général |
| 14 |
Erreur |
Emplacement du fichier de sortie non valide |
| 15 |
Erreur |
Le caractère d'échappement utilisé dans le fichier d'entrée , généralement un " ". |
Dépannage
Si une commande échoue, vérifiez les points suivants.
Délimiteur incorrect
Si le mauvais délimiteur est défini lorsque vous configurez une commande de transformation, la transformation ne s'exécutera pas comme prévu.
Ce n'est pas un vrai CSV
Si l'ensemble de données tabulaires n'est pas un CSV correct, la commande de transformation ne s'exécutera pas, car elle vérifie si le format est conforme à la RFC 4180 avant de traiter l'entrée. Un véritable CSV :
- Stocke les données en texte brut à l'aide d'un jeu de caractères tel que l'ASCII, l'Unicode (par exemple, UTF-8), l'EBCDIC ou le Shift JIS.
- Se compose d'enregistrements avec un enregistrement par ligne et d'enregistrements divisés en champs séparés par des délimiteurs, généralement un seul caractère réservé tel qu'une virgule, un point-virgule ou une tabulation. Le délimiteur peut parfois inclure des espaces facultatifs.
- Présente la même séquence de champs pour chaque enregistrement
- Il s'agit généralement d'un fichier plat ou d'un rapport de données relationnelles.
Nombre incohérent de colonnes dans chaque enregistrement
Si les enregistrements d'un ensemble de données tabulaires ont des nombres de colonnes différents, la commande de transformation détecte qu'il ne s'agit pas d'un véritable CSV.
Différents nombres de colonnes
La combinaison de deux ensembles de données tabulaires CSV appropriés avec des nombres de colonnes différents ne fonctionnera pas, et la commande Stack Files affichera une erreur.