To prepare delimiter-separated values (DSV) data for upload, such as to massage tabular data into the required format, add a step in a chain that uses a Tabular Transformation connection command. For example:
- Split datasets based upon content in a record
- Filter based on rules
- Combine datasets from multiple sources
To enable these commands, an IT admin first creates a Tabular Transformation connector.
Add header
To add a header row to a comma-separated values (CSV) file, use an Add Header command.
Properties
| Property |
Detail |
| Input file |
Enter the file to add the headers to. |
| Delimiter |
Select the delimiter used to separate columns in Input file. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
| Header row |
Enter the entire contents of the header row. Separate each header with a delimiter, such as Column1,Column2,Column3. |
| Header delimiter |
Enter the delimiter used to separate headers in Header row, such as ,
|
Outputs
| Output |
Output Type |
| CSV with headers |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
Add row numbers
To add row number to the DSV in the first column, use an Add Row Numbers command.
Properties
| Property |
Detail |
| Input file |
Enter the file to add row numbers to. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Enter the delimiter used to separate columns in Input file. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
Outputs
| Output |
Output Type |
| Add row numbers output |
File |
| Record Count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Advanced query
To execute a SQL query on one or more CSV files, use an Advanced Query command. You can also join other files that you attach to this command.
Note: This command supports SELECT statements and complementary JOIN statements, but not statements such as INSERT, UPDATE, or CREATE. To insert rows, use the Stack Files command; to update rows, Find and Replace.
Properties
| Property |
Detail |
| Tables |
Enter all of the files to use in the query, as well as their table name. |
| Query |
Enter the SQL query to execute, as SQLite syntax:
- If column names or identifiers contain spaces or special characters, use brackets. For example,
[Column A], [Column B].
- To format data with two decimal spaces, use the syntax
SELECT PRINTF('%.2f',(SUM(DATA))) AS EBITDA FROM HFMDat.
- To select the first instance of a duplicate, such as if two records have the same
ID, use the syntax select * from group by ID having MIN(ID) ORDER BY ID.
- To concatenate multiple strings together, use the
|| operator such as string1 || string2 [ || string_n ].
|
| Input delimiter |
Select the delimiter used in Tables, as well as the join files. |
| Output delimiter |
Select the delimiter to use in the query results. |
| Preview |
To print a preview of the query results, check this box. |
The Advanced Query command automatically tries to determine a column's data type. To retain any leading zeroes for a value the command mistakes for an integer, use Find and Replace commands—with Regex and Replace matches only selected—to add single-quotes (') around the column's values and then remove them after the Advanced Query command completes:
- To add single quotes, find
(\d+), and replace with '$1'.
- To remove single quotes, find
'(\d+)', and replace with $1.
With Regex selected, the Find and Replace command uses the parentheses (()) to capture the group or characters, and then replaces them as the first parameter $1. To create multiple captures, use subsequent sets of parentheses and incremental values such as $2.
Outputs
| Output |
Output Type |
| Result |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Change delimiter
To change the delimiter of a CSV file, use a Change Delimiter command.
Note: To comply with the RFC specification, always use a single character for a delimiter, preferably a comma or tab character.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Input delimiter |
Enter the delimiter currently used in Input file. For a tab character, enter \t. |
| Output delimiter |
Enter the delimiter to use after the transformation. For a tab character, enter \t. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
| Keep empty rows |
Check this box to maintain empty rows in your output. They're removed by default. |
Outputs
| Output |
Output Type |
| CSV result |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
Clean unquoted newlines
To attempt to clean a file that is Request for Comments (RFC)-compliant except for unquoted new line characters, use a Clean Unquoted Newlines command. For example, use this command to process data files with inconsistent characters for carriage returns or new lines.
Note: This command cleans only unquoted new lines. Other non-compliant issues will still cause the data set to fail.
Properties
| Property |
Detail |
| Preview result |
To preview the result in the command's log, check this box. |
| Input file |
Enter the file to clean. |
| File delimiter |
Select the delimiter for each column in Input file. |
| Use lazy quotes |
To enable quotes to appear in unquoted fields and non-double quotes to appear in quoted fields, check this box. |
| Append trailing text |
To append any single-column lines with no delimiters in Input file to the last value of the last column of the previous record, check this box. |
Outputs
| Output |
Output Type |
| Cleaned newlines output |
File |
| Line count |
Integer |
Note: The Line count output provides the total number of records—including the header—in the Cleaned newlines output output.
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Failed to create the cleaned newline output |
Column filter
To filter the DSV columns with headers that match the specified pattern, use a Column Filter command.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter used in Input file. |
| Pattern type |
Select the type of pattern to filter by:
-
Index to filter by column index
-
Exact to filter by a comma-separated list of exact values
-
Regex to filter by a regular expression
|
| Pattern |
Enter the pattern to match columns with. If Pattern type is Index, apply the spread operator, such as 1:5,7:8,10:15. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
| Inverse |
To keep the matched columns and remove all others, check this box. |
Outputs
| Output |
Output Type |
| Column filter output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Concat files
To merge multiple tabular data source files horizontally into a single CSV dataset, use a Concat Files command.
Properties
| Property |
Detail |
| Source files |
Enter the files to concatenate. |
| Preview result |
To preview the result in the command's log, check this box. |
| File delimiter |
Select the delimiter used in Source files. |
Outputs
| Output |
Output Type |
| Merged CSV |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Failed to generate CSV |
Convert CSV to XLSX
To convert a CSV file to a Microsoft Excel® workbook (XLSX), use a Convert CSV to XLSX command.
Properties
| Property |
Detail |
| Input file |
Enter the file to convert to XLSX. |
| Delimiter |
Select the delimiter used in Input file. |
| Sheet name |
Enter the name of the sheet to create in the Excel workbook. |
| Output file |
Enter the path to where to store the file (optional). If using as an output for another command in the chain, leave blank. |
Outputs
| Output |
Output Type |
| Output XLSX |
File |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
Convert JSON to CSV
To convert a JSON file to a CSV, use a Convert JSON to CSV command.
Properties
| Property |
Detail |
| Input file |
Enter the JSON file to convert to CSV. |
| Output file |
Enter the path to where to save the new CSV file. If using as an output for another command in the chain, leave blank. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
Outputs
| Output |
Output Type |
| Output CSV |
File |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
Convert to crosstab
To convert a tabular data set—such as an Oracle Essbase® multidimensional expressions (MDX) query output—to a cross-tabulation, or crosstab, format, use a Convert to Cross-Tab command. This command bases the crosstab layout on the column and row headers defined as tuples in the input tabular data set.
For example, with this command, this data set:
(Measures, Product, Market) (Actual, Qtr1) (Actual, Qtr2) (Actual, Qtr3) (Actual, Qtr4) (Budget, Qtr1) (Budget, Qtr2) (Budget, Qtr3) (Budget, Qtr4) (Sales, 100-10, New York) 1995.0 2358.0 2612.0 1972.0 2249.0 2220.0 2470.0 1720.0 (Sales, 100-10, Massachusetts) 1456.0 1719.0 1905.0 1438.0 1360.0 1620.0 1800.0 1250.0 (Sales, 100-10, Florida) 620.0 735.0 821.0 623.0 570.0 690.0 770.0 530.0 (Sales, 100-10, Connecticut) 944.0 799.0 708.0 927.0 880.0 750.0 660.0 810.0 (Sales, 100-10, New Hampshire) 353.0 413.0 459.0 345.0 320.0 370.0 430.0 280.0 (Sales, 100-10, California) 1998.0 2358.0 2612.0 1972.0 2480.0 2940.0 3250.0 2530.0 (Sales, 100-10, Oregon) 464.0 347.0 345.0 370.0 570.0 420.0 420.0 470.0
can become a tab-delimited crosstab:
Actual Actual Actual Actual Budget Budget Budget Budget
Qtr1 Qtr2 Qtr3 Qtr4 Qtr1 Qtr2 Qtr3 Qtr4
Sales 100-10 New York 1995.0 2358.0 2612.0 1972.0 2249.0 2220.0 2470.0 1720.0
Sales 100-10 Massachusetts 1456.0 1719.0 1905.0 1438.0 1360.0 1620.0 1800.0 1250.0
Sales 100-10 Florida 620.0 735.0 821.0 623.0 570.0 690.0 770.0 530.0
Sales 100-10 Connecticut 944.0 799.0 708.0 927.0 880.0 750.0 660.0 810.0
Sales 100-10 New Hampshire 353.0 413.0 459.0 345.0 320.0 370.0 430.0 280.0
Sales 100-10 California 1998.0 2358.0 2612.0 1972.0 2480.0 2940.0 3250.0 2530.0
Sales 100-10 Oregon 464.0 347.0 345.0 370.0 570.0 420.0 420.0 470.0
Sample configuration
The setup will look something like this:
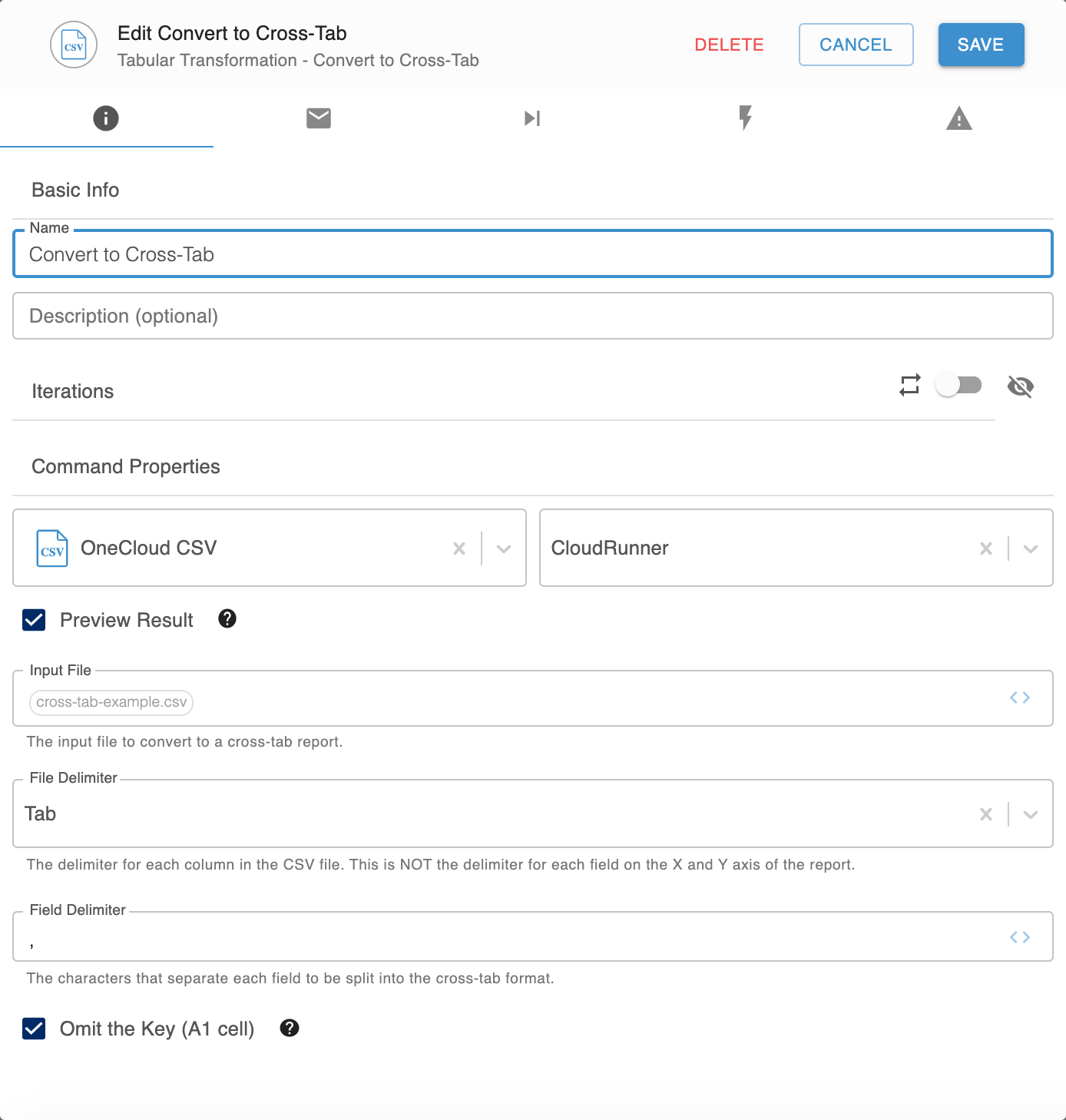
Properties
| Property |
Detail |
| Preview result |
To preview the crosstab format, check this box. |
| Input file |
Enter the file to convert to a crosstab format, with the column and row headers defined as tuples.
Note: Set up the input file so its first column is a delimited set of values to be spread horizontally, and its first row is a delimited set of values to be spread vertically.
|
| File delimiter |
Select the delimiter used with columns in Input file. |
| Field delimiter |
Enter the character to use to separate each field split into the crosstab format. |
| Omit the key (A1 cell) |
To omit cell A1 of Input File from the crosstab format, check this box. For example, if cell A1 contains (A,B), cells A1 and A2 of the cross tab format are blank; if not, they contain A and B. |
Outputs
| Output |
Output Type |
| Crosstab report |
File |
| Line count |
Integer |
Note: The Line count output provides the total number of lines in the Crosstab report output, including all header rows.
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
Convert XLSX to CSV
The Tabular Transformation version of this command has been discontinued. Any existing chains using this command will continue to function, but no future instances can be created.
Instead, we recommend using the Excel connector's Worksheet to CSV command.
Copy column
To copy a column from a DSV file, use a Copy Column command.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter used in Input file. |
| Column name |
Enter the name of the column to copy. |
| New column name |
Enter the name of the resulting copy of the column. |
| Insert index |
Enter the column index to insert the copy of the column at. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
Outputs
| Output |
Output Type |
| Copy column output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in the input file, usually a "
|
Extract value
To extract a value from a DSV file by the row index and column index, use an Extract Value command.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Delimiter |
Select the delimiter used in Input file. |
| Row index |
Enter the row number to extract the value from, with the first line in Input file being 1. |
| Column index |
Enter the column number of the Row index input to extract from. To extract the entire row, leave blank. |
Outputs
| Output |
Output Type |
| Row |
JSON |
| Value |
String |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
Filter rows
To filter rows of the DSV by a regular expression (regex) or exact match of one or more columns in the row, use a Filter Rows command.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter used in Input file. |
| Find pattern |
Enter the pattern to use to find matches. |
| Match pattern type |
Select whether to match by a Regex or Exact pattern. |
| Case insensitive |
To ignore the case of the text, check this box. |
| Inverse |
To keep all matched rows and discard the rest, check this box. |
| Search columns |
Enter a comma-separated list of column indexes to limit the search to. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box |
Note: The Filter Rows command expects a proper DSV file with headers. To filter out the first row of a file without headers, use the Find command of a File Utilities connection.
Outputs
| Output |
Output Type |
| Filter row output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Find and replace
To find and replace column values in the data based on a regular expression, full text string, or column index, use a Find and Replace command.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Specify whether to output the original file or a copy:
- To output the original file with its updated column values, enter the same file as Input file.
- To output a copy of the original with the updated column values, enter the name of the new file.
|
| Delimiter |
Select the delimiter used in Input file. |
| Find pattern |
Enter the regular expression, text string, or column index to use to identify values to replace, based on Match pattern type. |
| Match pattern type |
Select how to identify the column values to find:
- To find values based on a regular expression, select
Regex.
- To find values that match a full text string, select
Exact.
- To find values based on their column, select
Index.
Note: Exact matches the full string within each column. To find and replace a partial value with a column, select Regex and Replace matches only.
|
| Replacement value |
Enter the text to replace matched values with.
Note: If Match pattern type is Index, the replacement value replaces all of the matched column's values.
|
| Case insensitive |
To ignore the case of the text, check this box. |
| Replace matches only |
If Match pattern type is Regex, check this box to replace only the matching text with the replacement value. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
| Columns |
Enter a comma-separated list of columns to scope the command to, with 0 for the first column. For example, 0,1,2,3 limits the command to the first four columns. |
Note: To apply the same Replacement Value input to multiple values, use a regular expression as the Find Pattern input, such as (?:Variance|Variance %|All Periods|FY15|YTD).
Outputs
| Output |
Output Type |
| Find & replace output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Insert column
To insert a column into a DSV file, use an Insert Column command.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter used in Input file. |
| Header text |
Enter the name of the new column header. |
| Data value |
Enter the text to insert into the new column. |
| Insert index |
Enter the column index to insert the new column at. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
Note: To insert multiple columns, add a column to the input file with a header EMPTY_REPLACED_HEADER, with a value for each row of EMPTY_REPLACED_VALUE. With the File Utilities connection, use Find and Replace commands to replace the header placeholder with the desired column header, and the value placeholder with a string of the number of needed commas.
Outputs
| Output |
Output Type |
| Insert column output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Join columns
To join multiple columns of a DSV file and optionally discard the used columns, use a Join Columns command.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter of Input file. |
| Joined column index |
Enter the number index for the new column. For the first column, enter 0. |
| Match pattern type |
Select the type of pattern to search for columns by:
- To search by column location, select Index.
- To enter a comma-separated list of headers, select Exact.
- To use regular expression, select Regex.
|
| Match pattern |
Enter pattern or index to use to find the columns to join. |
| Joined column header |
Enter the name of the new column created from the join. |
| Join text |
Enter the text that joins the values together in the new column, such as -. |
| Discard |
To remove the columns joined to create the new one, check this box. |
| Preview results |
To preview the first 10 lines and header of the transformation's results, check this box. |
Outputs
| Output |
Output Type |
| Join column output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Map headers
To replace a list of headers with another list of headers, use a Map Headers command. In the lists, separate headers with commas, and order matters.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter of Input file. |
| Input headers |
Enter a list of the headers to replace with new values, in the same order as Output headers. |
| Output headers |
Enter a list of the new headers to include in the output, in the same order as Input headers. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
| Use indexes |
If Input headers uses numeric indexes, check this box. |
Outputs
| Output |
Output Type |
| Map headers output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Pivot
To represent the values in a data column as separate columns, use a Pivot command. When you pivot a column, its rows' unique values become new column headers.
For example, given this data:
YEAR,MEASURE,PRODUCT,MARKET,SCENARIO,Period,Amount
FY20,Sales,100-10,Massachusetts,Actual,JAN,125
FY20,Sales,100-10,Massachusetts,Actual,FEB,225
FY20,Sales,100-10,Massachusetts,Actual,MAR,325
FY20,Sales,100-10,Massachusetts,Actual,APR,425
FY20,Sales,100-10,Massachusetts,Actual,MAY,525
FY20,Sales,100-10,Massachusetts,Actual,JUN,625
FY20,Sales,100-10,Massachusetts,Actual,JUL,725
FY20,Sales,100-10,Massachusetts,Actual,AUG,825
FY20,Sales,100-10,Massachusetts,Actual,SEP,925
FY20,Sales,100-10,Massachusetts,Actual,OCT,1025
FY20,Sales,100-10,Massachusetts,Actual,NOV,1125
FY20,Sales,100-10,Massachusetts,Actual,DEC,1225
FY20,COGS,100-10,Massachusetts,Actual,JAN,100
FY20,COGS,100-10,Massachusetts,Actual,FEB,200
FY20,COGS,100-10,Massachusetts,Actual,MAR,300
FY20,COGS,100-10,Massachusetts,Actual,APR,400
FY20,COGS,100-10,Massachusetts,Actual,MAY,500
FY20,COGS,100-10,Massachusetts,Actual,JUN,600
FY20,COGS,100-10,Massachusetts,Actual,JUL,700
FY20,COGS,100-10,Massachusetts,Actual,AUG,800
FY20,COGS,100-10,Massachusetts,Actual,SEP,900
FY20,COGS,100-10,Massachusetts,Actual,OCT,1000
FY20,COGS,100-10,Massachusetts,Actual,NOV,1100
FY20,COGS,100-10,Massachusetts,Actual,DEC,1200
If you pivot the MEASURE column, aggregate the Amount column, and specify the remaining columns as rows, the output replaces the MEASURE column with columns for its Sales and COGS values and provides their respective amounts:
YEAR,PRODUCT,MARKET,SCENARIO,Period,Sales,COGS
FY20,100-10,Massachusetts,Actual,APR,425,400
FY20,100-10,Massachusetts,Actual,AUG,825,800
FY20,100-10,Massachusetts,Actual,DEC,1225,1200
FY20,100-10,Massachusetts,Actual,FEB,225,200
FY20,100-10,Massachusetts,Actual,JAN,125,100
FY20,100-10,Massachusetts,Actual,JUL,725,700
FY20,100-10,Massachusetts,Actual,JUN,625,600
FY20,100-10,Massachusetts,Actual,MAR,325,300
FY20,100-10,Massachusetts,Actual,MAY,525,500
FY20,100-10,Massachusetts,Actual,NOV,1125,1100
FY20,100-10,Massachusetts,Actual,OCT,1025,1000
FY20,100-10,Massachusetts,Actual,SEP,925,900
If you exclude the Period column from the rows, all time periods aggregate for each combination of the remaining rows:
YEAR,PRODUCT,MARKET,SCENARIO,Sales,COGS
FY20,100-10,Massachusetts,Actual,8100,7800
If you pivot both the MEASURE and Period columns, each unique combination of their values appears as columns, such as Sales-JAN, Sales-FEB, COGS-JAN, and so on:
YEAR,PRODUCT,MARKET,SCENARIO,Sales-JAN,Sales-FEB,Sales-MAR,Sales-APR,Sales-MAY,Sales-JUN,Sales-JUL,Sales-AUG,Sales-SEP,Sales-OCT,Sales-NOV,Sales-DEC,COGS-JAN,COGS-FEB,COGS-MAR,COGS-APR,COGS-MAY,COGS-JUN,COGS-JUL,COGS-AUG,COGS-SEP,COGS-OCT,COGS-NOV,COGS-DEC
FY20,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225,100,200,300,400,500,600,700,800,900,1000,1100,1200
Properties
| Property |
Detail |
| Input file |
Enter the file with the data to pivot. |
| Delimiter |
Select the delimiter used to separate fields in Input file. |
| Aggregation |
Select how to aggregate pivoted values:
-
SUM, to collapse records with the same row values into a single record. Recommended.
-
NONE, to create multiple rows for a single set of equivalent values. Each row of the pivoted column will be populated, but others may include NULL.
|
| Values to aggregate |
Enter the column with the data to include in the pivoted columns' rows, such as the Amount column in the earlier example. |
| Pivot columns |
Enter the columns with row values to use as column headers. If multiple columns, a separate column appears for each unique combination of their values. |
| Column delimiter |
If multiple Pivot columns, enter the delimiter to use to separate their values in the new column headers. |
| Pivot rows |
Enter the columns in Input file to retain. In the output, each unique combination of these columns' values appear as rows. Do not enter the same columns as Values to aggregate or Pivot columns. |
| Preview results |
To enable a preview of pivoted data, check this box. |
Outputs
| Output |
Output Type |
| Pivoted result |
File |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input file, usually a "
|
Reorder columns
To rearrange a DSV file's columns, use a Reorder columns command. You can identify columns by their name or index.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Delimiter |
Select the delimiter used in Input file. |
| Column orders |
Enter an array of the individual columns or ranges from Input file, in the order they should appear in the transformed file. To specify columns, use their name or index, starting with 1. For example, enter 4:6 or ColA:ColC to specify a range, or 7 or ColH for an individual column.
Note: Any columns in Input file not included in Column orders appear at the end of the transformed file's columns, in the same order as in Input file.
|
| Preview results |
To show a preview of the results—the header and first 10 rows—in the command output, check this box. |
Outputs
| Output |
Output Type |
| Transformed file |
File |
| Transformed rows |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
Smart filter rows
To apply multiple filter groups' criteria—based on text, date, or number values—to the rows of a DSV file, use a Smart Filter Rows command. You can filter rows by regular expression or an exact match of one or more of their columns.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter used in Input file. |
| Inverse |
To keep—rather than remove—all rows that match Filters, check this box. |
| Filters |
To set up the text, number, or date filters to apply to Input file, select the operator for the filter groups—AND or OR—and configure the criteria for each.
For a text filter group:
- In Column Name, enter the name of the column to filter.
- To ignore the casing of Column Name and Compare Text, select Case Insensitive.
- In Condition and Compare Text, enter the criteria of the value to search the column for, such as "Equals [text]" or "Contains [text]".
For a number filter group:
- In Format, select the format of the number to match—Integer or Decimal. If it could be either, select Decimal.
- In Column Name, enter the name of the column to filter.
- In Condition and Test Number, enter the criteria of the value to search the column for, such as "Equals [number]" or "Less than [number]".
For a date filter group:
- In Format, enter January 2, 2006 in the format of the date to match, such as 2006-01-02.
- In Column Name, enter the name of the column to filter.
- In Condition and Compare Date, enter the criteria of the value to search the column for, such as "Equals [date]" or "Less than [date]".
|
| Preview results |
To show a preview of the results in the command output, check this box. |
Outputs
| Output |
Output Type |
| Smart filter row output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Split file
To split a file into multiple files based on a record count, use a Split File command. For example, use this command to process smaller chunks in parallel to help improve performance
Properties
| Property |
Detail |
| Input file |
Enter the file to split into multiple files. |
| File delimiter |
Select the delimiter for each column in Input file. |
| Prepend header |
To include the header of Input file in each file chunk created, check this box. |
| Records per file |
Enter the maximum number of records to include in each file chunk. |
Outputs
| Output |
Output Type |
| Split file chunks |
File |
| Number of chunks |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Failed to create the file chunks |
Split value
To split a column into multiple columns given a value delimiter, use a Split Value command.
Properties
| Property |
Detail |
| Input file |
Enter the file to transform. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter used to separate columns in Input file. |
| New headers |
Enter a list of the new headers to create from the split value, in order. |
| Column name |
Enter the header of the column to split. |
| Value delimiter |
Enter the delimiter to split the value on. |
| Discard column |
To remove the column being split, check this box. |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
Outputs
| Output |
Output Type |
| Split values output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input file, usually a "
|
Stack Files
To stack the values from a list of delimiter-separated values (DSV) files on top of each other in a specified order, use a Stack Files command. The header row from the first file will be used in the new file.
Note: To stack files with this command, they must all have the same number of columns. To stack asymmetric files, use the File Utils connector and its Stack Files command.
Properties
| Property |
Detail |
| Files |
Enter the DSV files to stack. |
| Output file |
Enter the name of the resulting file of the transformation. |
| Delimiter |
Select the delimiter used to separate columns in Files. |
| Input file |
Enter the files to stack, separated by a comma.
Note: When using a loop, this field is required (due to the files not being uploaded in the Files section). The command will trigger a "file not found" error if added to the Files section instead.
|
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
Outputs
| Output |
Output Type |
| Stack files output |
File |
| Record count |
Integer |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input file, usually a "
|
Transpose
To rotate all fields of a delimited file along its horizontal and vertical axis, so rows become columns and vice versa, use a Transpose command. For example, with this command, this CSV:
id,1,2,3,4
name,"Johnson, Smith, and Jones Co.","Sam Smith",Barney & Co.,Johnson's Auto
amount,345.33,933.40,0,2344
remark,Pays on time,,"Great to work with.",
becomes:
id,name,amount,remark
1,"Johnson, Smith, and Jones Co",345.33,Pays on time
2,"Sam Smith",933.40,
3,Barney & Co.,"Great to work with."
4,Johnson's Auto,2344,
Properties
| Property |
Detail |
| Preview results |
To preview the first ten lines and header of the transformation's results, check this box. |
| Input file |
Enter the delimited file to transpose. |
| File delimiter |
Select the delimiter of each column of Input file. |
| Chunk size |
Enter the maximum size—in mb—of each working file for processing. |
Outputs
| Output |
Output Type |
| Transposed CSV |
File |
| Record count |
Integer |
Note: Record Count provides the total number of lines in Transposed CSV, not including the header row.
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Failed to transpose the input file |
Unpivot
To consolidate multiple columns of data—such as time periods in financial data—into a single column with multiple rows, use an Unpivot command. For example, given this data:
YEAR,MEASURE,PRODUCT,MARKET,SCENARIO,JAN,FEB,MAR,APR,MAY,JUN,JUL,AUG,SEP,OCT,NOV,DEC
FY20,Sales,100-10,New York,Actual,100,200,300,400,500,600,700,800,900,1000,1100,1200
FY20,Sales,100-10,Massachusetts,Actual,125,225,325,425,525,625,725,825,925,1025,1125,1225
You can unpivot the monthly amounts into new Period and Amount columns:
YEAR,MEASURE,PRODUCT,MARKET,SCENARIO,Period,Amount
FY20,Sales,100-10,Massachusetts,Actual,JAN,125
FY20,Sales,100-10,Massachusetts,Actual,FEB,225
FY20,Sales,100-10,Massachusetts,Actual,MAR,325
FY20,Sales,100-10,Massachusetts,Actual,APR,425
FY20,Sales,100-10,Massachusetts,Actual,MAY,525
FY20,Sales,100-10,Massachusetts,Actual,JUN,625
FY20,Sales,100-10,Massachusetts,Actual,JUL,725
FY20,Sales,100-10,Massachusetts,Actual,AUG,825
FY20,Sales,100-10,Massachusetts,Actual,SEP,925
FY20,Sales,100-10,Massachusetts,Actual,OCT,1025
FY20,Sales,100-10,Massachusetts,Actual,NOV,1125
FY20,Sales,100-10,Massachusetts,Actual,DEC,1225
FY20,Sales,100-10,New York,Actual,JAN,100
FY20,Sales,100-10,New York,Actual,FEB,200
FY20,Sales,100-10,New York,Actual,MAR,300
FY20,Sales,100-10,New York,Actual,APR,400
FY20,Sales,100-10,New York,Actual,MAY,500
FY20,Sales,100-10,New York,Actual,JUN,600
FY20,Sales,100-10,New York,Actual,JUL,700
FY20,Sales,100-10,New York,Actual,AUG,800
FY20,Sales,100-10,New York,Actual,SEP,900
FY20,Sales,100-10,New York,Actual,OCT,1000
FY20,Sales,100-10,New York,Actual,NOV,1100
FY20,Sales,100-10,New York,Actual,DEC,1200
Properties
| Property |
Detail |
| Input file |
Enter the file with data to unpivot. |
| Delimiter |
Select the delimiter used to separate fields in Input file. |
| Aggregation |
Select how to aggregate unpivoted values:
-
SUM, to aggregate records when their values are the same across all columns. Recommended.
-
NONE, to create duplicate rows with the unique data value from each record.
|
| New column label |
Enter the header for the column in the output with rows based on the unpivoted columns. In the earlier example, Period. |
| Data column header |
Enter the header for the column in the output with data for the unpivoted columns. In the earlier example, Amount. |
| Data headers |
To unpivot specific columns, list their headers, pressing Enter between each. In the earlier example, JAN, FEB, MAR, and so on. |
| Starting pivot column name |
To unpivot a range of columns by header, enter the name of the first column of the range. In the earlier example, JAN. |
| Ending pivot column name |
To unpivot a range of columns by header, enter the name of the last column of the range. In the earlier example, DEC.
Note: If you enter Starting pivot column name but no Ending pivot column name, the command unpivots it and all columns to the right of Starting pivot column name. This can be useful with data produced by rolling forecasts.
|
| Starting pivot column index |
To unpivot a range of columns by position, enter the index value of the first column in the range. Use a zero-based index, where the columns in Input file start with 0. In the earlier example, 5. |
| Ending pivot column index |
To unpivot a range of columns by position, enter the index value of last column of the range. Use a zero-based index, where the columns in Input file start with 0. In the earlier example, 16.
Note: If you enter Starting pivot column index but no Ending pivot column index, the command unpivots it and all columns to the right of Starting pivot column index. This can be useful with data produced by rolling forecasts.
|
| Preview results |
To enable a preview of the unpivoted output, check this box. |
Outputs
| Output |
Output Type |
| Unpivoted result |
File |
Exit codes
| Code |
Type |
Detail |
| 0 |
Success |
Success |
| 1 |
Error |
Invalid arguments |
| 2 |
Error |
General failure |
| 14 |
Error |
Invalid output file location |
| 15 |
Error |
The escape character used in Input File, usually a "
|
Troubleshooting
If a command fails, check for these common issues.
Wrong delimiter
If the wrong delimiter is set when you configure a transformation command, the transformation won't execute as expected.
Not a proper CSV
If the tabular dataset isn't a proper CSV, the transformation command won't execute, as it checks to see if the format complies with RFC 4180 before it processes the input. A proper CSV:
- Stores data in plain text using a character set such as ASCII, Unicode (e.g., UTF-8), EBCDIC, or Shift JIS.
- Consists of records with one record per line, and records divided into fields separated by delimiters, typically a single reserved characters such as a comma, semicolon, or tab. Sometimes the delimiter may include optional spaces.
- Has the same sequence of fields for every record
- Is typically a flat file or relational data report output
Inconsistent number of columns in each record
If the records in a tabular dataset have different column counts, the transformation command detects that it isn't a proper CSV.
Different column counts
Combining two proper CSV tabular datasets with different column counts won't work, and the Stack Files command will display an error.